
Email Tom
Tom's Website


Email Brian
Brian's Website
|
Email Tom Tom's Website |
|
Email Brian Brian's Website |
Go to the Table Of Contents
Did you read the Preface? Thanks!
Scripts are integral to the proper functioning and health of your GNU/Linux system. Shell scripts are most common; they are used for many purposes, including sequencing and running numerous tasks upon Linux system startup. Scripts are also used for system and process maintenance purposes. For scripted text processing, the original dynamic duo is awk and sed. Perl, a more recent scripting language designed for text processing and report creation, has since taken over as the premier scripting tool in the Webmaster's toolbox, and is used in system scripts as well. For scripting in a graphical environment, the best-known tool is Tcl/Tk.
Shell scripts are easy to use, as you can see in this example (line numbers added for clarity):
1 #!/bin/sh
2 # shell script example 1
3 # filename: easy
4 echo -e "I'm sorry, Tom. I can't do that.\a\n"
The first line is a bit of magic. It tells the current shell to execute the script in the environment specified on the first line, a fully qualified path/filename. In the case of the previous example, we call /bin/sh, which is a symlink to /bin/bash. Scripts are written to meet various needs, and the different shells have different strengths. For instance, the shell programming environment of the C Shell (/bin/csh) is very like the language C, which eases the transition for practiced C programmers. A first line of #!/bin/csh runs a script in a C Shell context.
For the previous example, create the file called 'easy' with any text editor (omitting the line numbers), save it to disk, make the file executable, then execute the script:
[syroid@janus syroid]$ chmod a+x easy
[syroid@janus syroid]$ ./easy
I'm sorry, Tom. I can't do that.
As you can see from the output, this script simply uses the echo -e command on the fourth line to display the quoted string. The "-e" is used to enable the escape code sequences: \a beeps the system speaker (just for fun), and \n terminates the string with a newline. The second and third script lines are comments, and should be used liberally to document the script's name, the purpose of any non-intuitive commands, etc. The fourth line of the script is the meat of the example, short as it is. In addition, there are a number of escape characters that can be enabled by use of the -e option; more on this topic shortly.
At a basic level, shell scripts provide functionality similar to that of batch files in the DOS environment. However, due to the inherent design of bash (as well as other shells like ksh and csh), scripts are very powerful programmatic tools, and integral to the operation of Linux.
Any mindless, repetitive task is especially fair game for scripting. Take the following scenario, for example. A directory full of images needs to be modified. Among other tasks, the filenames, which are mixed case, need to be converted to lower case. By hand, one, two or five files aren't so tough to list and change. A hundred files is a painful prospect. Here's one possible script solution (note the liberal use of comments to document key lines):
1 #!/bin/sh
2 # Note the magic first line - set the shell context
3 # shell script example 2
4 # filename: fn2lower
5
6 # traverse $*, the list of arguments from the command line
7 for oldfile in $*
8 do
9 # use the tr command to lowercase the filename
10 newfile=` echo $oldfile | tr "[A-Z]" "[a-z]" `
11 # check that the filename is different
12 if [ "$oldfile" != "$newfile" ]
13 then
14 # make sure that we don't overwrite an existing file
15 if [ -e "$newfile" ]
16 then
17 echo -e "Can't rename $oldfile, $newfile exists"
18 else
19 # all is well, change the filename
20 mv $oldfile $newfile
21 fi
22 fi
23 done
There are a couple of tricks built into the preceding script. For instance, unless you are a programmer (or work with Boolean expressions), you might not know that != means "is not equal to." Also, the Left Bracket '[' used in lines 12 and 15 is actually a command alias for the bash built-in command test, discussed in the upcoming table. As with the first example, the line numbers are for reference only; do not enter them if you test this script yourself. Here's a demonstration of fn2lower in action:
[syroid@janus tjpg]$ chmod +x fn2lower
[syroid@janus tjpg]$ ls
JerryHall.jpg KeithRICHARDS.jpg Mick1.jpg fn2lower
JerryHall.txt Keith_R.jpg MickJagger.jpg mick1.jpg
[syroid@janus tjpg]$ ./fn2lower
Can't rename Mick1.jpg, mick1.jpg exists
[syroid@janus tjpg]$ ls
JerryHall.txt fn2lower keith_r.jpg mick1.jpg
Mick1.jpg jerryhall.jpg keithrichards.jpg mickjagger.jpg
After making the newly created script executable, it works as advertised, including the notification when it can't do its job. There's no output for success, just for failure. As you can see from the error message printed as the script executes, Mick1.jpg is not renamed because there is a pre-existing mick1.jpg file - This is *nix, so case matters. There are literally hundreds of ways to accomplish this task in an automated manner; this is just one.
In Chapter 15, among other topics, we looked at the bash shell and the built-in commands that bash offers for the interactive user on the command line. All of those commands can also be used in scripts. Table 18-1 lists the bash built-in commands that seem explicitly targeted at programmed scripts.
Table 18-1
bash Built-in Commands for Scripting
| Command | Description |
. |
Synonym for the source built-in command |
# |
Marks the rest of a line as a comment (see the next row for a special case) |
#!/pathto/shell |
Specifies that the named shell is to be invoked as a sub-shell, requires a fully qualified path name |
: |
Null command, returns 0 |
[ condition ] |
Alternative usage for the test built-in command |
break [n] |
Exits immediately from innermost n loop(s) (for, while or until), n defaults to 1 if not given |
built-in command [args] |
Execute built-in shell command, used when shell command has the same name as a script |
case ... |
Usage:
case string
in
regex)
commands
;;
...
esacCompare string to each regex in turn, executed commands from first match. Use * as final regex for default commands to be run. Observe the ')' following regex. |
command |
Usage: command [options] command [args] Run command, either from $PATH or built-in, no function lookups |
continue [n] |
Skip over the remaining commands in the innermost loop (for, while or until), n times (default 1). Resume execution at beginning of loop |
dirs [options] |
Output list of currently pushed (pushd) directories. |
for ... |
Usage:
for x in list
do
commands
doneExecute commands once for each item in list. x is set to each value in list, in turn. If "in list" is not present, script command line argument parameters, ($1, $2, etc) are assumed |
function [command] { ... } |
Define a function, may be multi-line. Conceptually between an alias and a script - may be sourced into the current operating environment. It can take arguments, and the functions don't require a sub-shell |
getopts string name [args] |
Used for script option (-x -y -z) processing |
if ... |
Usage:
if test-condition
then
commands
elif test-condition
then
commands
...
else
commands
fiTest condition uses the test built-in command, elif and else are optional. If test condition is met, execute the commands following, and then continue execution after the fi. Otherwise proceed to the next test condition. |
let expression |
Perform arithmetic expressions and assignment, for example:let maxfilecount=currentfilecount+100 |
local [variable[=value]] ... |
Print (and optionally set) local variables. Useful for examining or setting up script environment |
popd [+n | -n] |
From the directory stack, pop (remove the old) and cd to the new top entry on the stack. +n to remove nth item from the top, -n to remove nth item from the bottom of the stack |
pushd [directory] [+n | -n] |
Executed without argument, swap the top two entries of the directory stack, cd to the new top entry. Specify directory to change to it, pushing onto the top of the stack. +n to swap top with nth item from the top, -n to swap top entry with nth item from the bottom. |
read [-r] variable ... |
Read values from the command line, inserting words into variable(s). When one variable is left, balance of line gets read into variable (making it a list). -r forces raw read (no line continuation using '\') |
readonly [opts] variable[=value] |
Sets variable(s) to read only using -f option. New variables may be set once using the variable=value syntax. Use -p option alone to display all read-only variables |
return [n] |
Return from a function, either with return value of the most recently executed command, or with value n if specified |
select ... |
Usage:
select variable in list
do
commands
doneWords from list are presented in numbered list format on display, user is prompted for selection. User response is stored in REPLY, selected word is placed in variable. Commands are executed until break or return is encountered. |
shift [n] |
Left shift arguments as presented to script. For example, when $1 = file1 and $2 = file2, after shift, then $1 = file2. Optionally shift n places at one time. |
source file [args] or
. file [args] |
Execute the lines in file, in the current shell if no sub-shell is specified. file must be on PATH, or a fully qualified path/file combination. |
test condition or |
Return 0 if condition is satisfied (true). condition is built from a variety of expressions, testing features of files, string, or integer comparisons. Boolean operations can be performed on multiple expressions - see man bash for more details. |
trap [-l] [[cmds] signals] |
Traps signals sent to shell. Commands (cmds) are semicolon-separated and quoted as a group. For example, display a log file when a shell program exits, is interrupted, killed, or is at user logout:trap "cat $LOGFILE ; exit" 0 1 2 15 |
unset [-f] names |
Erase functions (-f) or variables (default, -v). |
until ... |
Usage:
until test-condition(s)
do
commands
doneExecute commands until test-condition(s) are met, or a break or return are encountered in commands |
while ... |
Usage:
while test-condition(s)
do
commands
doneExecute commands while test-condition(s) are met, or a break or return are encountered in commands |
These commands are used in concert with those listed in Chapter 17, where the Bash commands that are more likely used in interactive (shell) mode are given. If we've shown your favorite command line function here (like source or ".", for some), sorry: we imply no second rate citizenship.
The bash shell commands combine to make a powerful programming environment, especially taken in conjunction with pipes, redirection, and filters. Let's dive into those next.
Normal interactive use of process pipes on the command line usually looks something like this:
[syroid@janus syroid]$ ps -aux | grep netscape
syroid 1101 0.4 5.7 23264 7328 ? S 11:29 1:31 /opt/netscape/com
syroid 4872 0.0 0.3 1200 416 pts/1 S 16:57 0:00 grep netscape
The preceding command runs the ps program, passing the output to the grep command, which in turn parses any lines that include the sub-string "netscape." This example is useful for reducing a multi-screen listing to the bits that are relevant. In this case, it is reasonably quick to type and short enough that it is easy to remember. For longer one-line commands, or commands that are used frequently, then a command alias (as discussed in Chapter 15) is usually appropriate. For example:
[syroid@janus syroid]$ alias psg='ps -aux | grep $1'
[syroid@janus syroid]$ psg netscape
syroid 1101 0.4 5.7 23264 7328 ? S 11:29 1:31 /opt/netscape/com...
syroid 4929 0.0 0.3 1200 416 pts/1 S 17:01 0:00 grep netscape
Hint
In OpenLinux, you can put aliases in the bash initialization script ~/.bashrc_private, and they will be available at every subsequent terminal and login session for that user. The normal location is the file ~/.bashrc, (which recommends the former, but tacitly allows itself to be a valid location for user initialization code).
But "How does this relate to scripts?" you ask. Suppose you had a need to run this same command every hour and log the output to a file. Neither of us are going to sit there and execute this alias every hour, and how does the output get logged to a file, anyway?
To begin with, let's review some material from Chapter 15. The pipe symbol is | and I/O (Input/Output) redirection is accomplished with the '>', '<', and '&' characters. To pipe data means to take the output of one program, normally destined for the display (STDOUT stream or &1), and instead "pipe" it into the input (STDIN stream or &0) of another program. In one sense, pipes are a specialized form of redirection.
Redirection proper allows programs that are stream-oriented to have their inputs and outputs sent to locations other than the default. The default streams are as follows (listed by their file descriptor numbers):
0 Standard Input (STDIN), usually the keyboard
1 Standard Output (STDOUT), usually the display or terminal
2 Standard Error (STDERR), usually the display or terminal
With these streams to work with, I/O redirection and piping is accomplished using the small character set in combination with files and programs to achieve a wide variety of effects, many of which are listed here:
< fileSend contents of file as STDIN
n< fileSet file to act as file descriptor n
> filePuts STDOUT into file, overwrite
>| fileAs > file, but override the noclobber1 shell variable
n> filePuts file descriptor n output into file
n>| filePuts file descriptor n output into file, ignore noclobber
>> fileAppends STDOUT to file, creating if not present
cmd1 | cmd2Pipe, cmd1 STDOUT redirected to cmd1 STDIN
>&nDuplicate STDOUT to file descriptor n
&>fileSend both STDOUT and STDERR to file
Recall that the goal is to regularly monitor the Netscape process. By looking at the output at the beginning of this section, you might think that changing the grep pattern to "opt/netscape" isolates the actual Netscape process:
[syroid@janus syroid]$ ps -aux | grep "opt/netscape"
syroid 1101 0.4 5.7 23264 7328 ? S 11:29 1:31 /opt/netscape/com...
syroid 4872 0.0 0.3 1200 416 pts/1 S 16:57 0:00 grep opt/netscape
Hmm. Let's try something a little different:
[syroid@janus syroid]$ ps -aux | grep netscape | grep -v grep
syroid 1101 0.4 5.7 23264 7328 ? S 11:29 1:31 /opt/netscape/com...
Aha. Now we're down to one line of output, pertaining to the process that we want to monitor. We've taken advantage of the -v option of grep, which performs an inverse match. That is, it excludes lines containing the given term. Voila!
On the other hand, it is possible that we might still get more than one line of output if something were wrong. That is, perhaps a dead copy of Netscape is running, or multiple users are on the system each running separate instances of Netscape. Such events would be interesting to capture as well. Now send the output to a file, for instance /tmp/nsrun.log, an entirely imaginary file. To do this, add " >> /tmp/nsrun.log" (append STDOUT to file) to the end of the command. Assemble all the pieces:
1 #!/bin/sh
2 # shell script example 3
3 # filename: nslogger
4 ps -aux | grep netscape | grep -v grep >> /tmp/nsrun.log
Make the file executable (chmod u+x nslogger). Running the script manually several times places output similar to the following in the file nsrun.log:
[syroid@janus syroid]$ cat /tmp/nsrun.log
syroid 1101 0.4 9.6 23264 7328 ? S 11:29 1:52 /opt/netscape/com...
syroid 1101 0.4 9.6 23264 7328 ? S 11:29 1:52 /opt/netscape/com...
syroid 1101 0.5 16.7 34044 21412 ? S 11:29 2:11 /opt/netscape/com...
syroid 1101 0.5 16.7 34044 21412 ? S 11:29 3:45 /opt/netscape/com...
Boring, but if a log is needed of the times when Netscape is running, then this is a possible tool. Of course, the script is not much use if we can't run it at regular intervals and without user intervention. That is a job for the cron daemon.
Cron is a system service that is installed and running by default on many Linux distributions. (Let's be clear - We don't know of ANY distro that doesn't install cron or it's cousin, anacron, and run it by default - but with tens of distros out there, it's best to hedge our bets.) Cron's executing process can be observed by typing ps -ax | grep cron. If Cron isn't running, then there may be a problem with your installation - see Chapter 19 for assistance.
Cron is a tool for periodically running system and user-specified commands at intervals ranging in scale from minutes to months. While standard Unix programs with arguments can be run by Cron, it is considerably more common to have Cron execute scripts to accomplish complex tasks at regular intervals. To submit a Cron job as a user, the crontab program (see details on crontab in Chapter 17) is employed.
From the previous example, let's assume we want to know, at 15-minute intervals, the state of Netscape, and log it if it's running (or at least present in the process table). We already have the script we want; let's develop one more to rotate the log every week and retain one back week of data.
1 #!/bin/sh
2 # shell script example 4
3 # filename: nslogrot
4 # forced overwrite of prior backup log
5 mv -f /tmp/nsrun.log /tmp/nsrun.log.1
We set these two scripts, nslogger and nslogrot to be user-executable (chmod u+x nslog*) and move them to a new subdirectory, /home/syroid/scripts. The following lines entered in the crontab editor complete the setup.
0,15,30,45 * * * * /home/syroid/scripts/nslogger
05 03 * * 0 /home/syroid/scripts/nslogrot
So nslogger runs every 15 minutes, forever (but only while the system is running -- sometimes this is forgotten when examining logs). And on Day 0 of each week, Sunday, at 3:05 a.m. system time, the logs are rotated.
Note
There is a system facility for automating log rotation, type man logrotate for all the details. It's simple to use, and essential for system administration. But it would have made this example exactly half as interesting, so...
Here's another sample of a script that Cron executes on one of our systems (in this case, at just past midnight, each night):
1 #!/bin/sh
2 # /root/scripts/backup
3 # backup key system files and home dirs
4 # also dirs from db win98 machine, mounted using samba
5 # erase, retension, tar then rewind is the order of ops
6 #
7
8
9 # mount the db LARGE partition, using samba
10 smbmount //db/LARGE /mnt/mdocs -N
11
12 mt retension
13 mt erase
14 mt rewind
15
16 # do the backup, each dir to be backed up on a separate line
17 tar zcf /dev/tape \
18 /etc \
19 /home \
20 "/mnt/mdocs/My Documents" \
21 "/mnt/mdocs/Program Files/Netscape/Users"
22 sleep 300
23 mt rewind
24
25 smbumount /mnt/mdocs
There are three methods for executing scripts. We have examined several examples of the first type, which is to make the script executable and run it from the command line. When a script is executed directly from the command line, it runs in a sub-shell, specified with the magical shebang ('#!') on the first line of the script.
1 #!/bin/sh
2 # example script 5
3 # filename: seltest
4 #
5 echo "Are you older than:"
6 select VARNAME in Forty Fifty Sixty;
7 do
8 echo VARNAME
9 done
That's another boring script, which has the advantage of not terminating. After making the file executable, start it running by typing './seltest' (leave off the single quotes). Switching to another terminal and typing ps -ax | grep seltest yields the following results:
5144 pts/0 S 0:00 sh ./seltest
That's seltest running in its own shell. Switching back to the original terminal, seltest can be killed by pressing Ctrl+C.
Linux FAQ
Here's a common question: Why not just typeseltest(or any local directory executable file name) at the command line? This query usually results from the user's memory of running programs from DOS prompts, where .exe, .com and .bat files can be executed from anywhere on the path, as well as in the current directory. For reasons of security, this type of behavior is not default in Linux. To execute a program that is not in the$PATH, an explicit path to the executable must be given. The quickest shortcut to an explicit path into the current directory is "./", effectively, "a member of this directory."
Alternatively, a script that doesn't have the magic shell specification as its first line can be executed by running it as an argument to an explicitly specified shell. Now we make it non-executable by typing chmod a-x seltest. Then (merging the output of two different virtual terminals) we can see the following behavior:
[syroid@janus scripts]$ ./seltest
bash: ./seltest: Permission denied
[syroid@janus scripts]$ sh seltest
Are you older than:
1) Forty
2) Fifty
3) Sixty
#?
* * *
[syroid@janus scripts]$ ps -ax | grep seltest
5159 pts/0 S 0:00 sh seltest
5161 pts/2 S 0:00 grep seltest
Once the executable permission is removed from seltest, it cannot be directly executed. As shown on the second command line, it can be submitted to a shell as an argument and executed indirectly. The results of this are shown in the output of the ps/grep pipe in the third portion of the previous sample.
The final method of execution is to source a file. The purpose of sourcing a file is to have the effects of its execution last beyond the termination of the script. Here's another way of saying that - execute the script in the context of the current shell, rather than running it in a sub-shell. If the latter, then the script's effects terminate when the sub-shell does.
For example, suppose that you often change directories to a part of the kernel source tree (say, /usr/src/linux/drivers/usb/), to work on a bit of code. While doing so, you also change your PATH variable to give access to a couple of tools in /usr/local/special/bin/. This is a real pain to type every day. So write a script, make it executable, and put it in a directory on the PATH.
1 #!/bin/sh
2 # example script 6
3 # filename: dev
4 #
5 cd /usr/src/linux/drivers/usb
6 export PATH=$PATH:/usr/local/special/bin/
Now run dev from the command line and watch what happens:
[syroid@janus syroid]$ ./dev
[syroid@janus syroid]$
The command appears to fail - the directory remains unchanged, as does the path. Hmmm. Now, instead, source the file, either by typing source dev, or using the '.' alias (as the reader, you can call this the "dot" alias or the "period" alias, or for radio/floating point math aficionados, the "point" alias might work for you) for the source command:
[syroid@janus syroid]$ . dev
[syroid@janus usb]$ echo $PATH
/bin:/usr/bin:/usr/local/bin: ... :/usr/local/special/bin
Success. This method works by executing the contents of the file in the current shell, which means that any changes made in the environment carry forward (along with any side-effects, desirable or not).
To recap, a script file can be run by making it executable and running it directly from the shell. Alternately, a script can be run as an explicit argument to a shell, it can be sourced, or the script can execute within the context of the current shell.
Shell Script Resources
On OpenLinux
From the command line, typeman bash, orman csh, orman ksh- whichever shell environment you're writing for. A recommendation: We've heard the following phrase often enough to repeat it for you: "csh programming considered harmful". A Google search on that phrase should give you a few good links.Online
Dr. Andrew Hunter has posted this most useful page at http://osiris.sund.ac.uk/ahu/comm57/script.htmlInk on Dead Trees
UNIX Shell Programming, Fourth Edition, by Lowell Jay Arthur and Ted Burns (John Wiley & Sons, 1997)
UNIX Power Tools, Jerry Peek, Tim O'Reilly, and Mick Loukides (O'Reilly and Associates, 1997).
Learning The Bash Shell, by Cameron Newham and Bill Rosenblatt (O'Reilly and Associates, 1998).
Now we're in for some fun! sed is a stream-oriented text editor, and gawk is a pattern matching utility. These tools are used both on the command line and frequently in scripts. Regular expressions (or regex's) make several appearances in the coming pages - we discussed them briefly in Chapter 17. You can also find more information about regex pattern matching in the ed manual page. Now, let's talk about sed.
sedThis handy little command took every instance of the string "Brian Bilbrey" out of the file book.old, replacing it with the string "Tom Syroid," and redirected the output into the file book.new. Text replacement is a common use of sed on the command line.
[Hey, wait a minute, there's something wrong about that example... bpb]
The calling options and command syntax for sed are surprisingly sparse.
sed - a Stream EDitor
Usage : sed [options] [script | -e script... | -f sfile] [inputfile... | -]
|
|
-V | --version |
Display sed version information and copyright then exit |
-h | --help |
Display a brief usage summary and options, then exit |
-n | --quiet | --silent |
sed output defaults to STDOUT; this option disables output, requiring explicit printing of output in sed commands |
-e script | --expression=script |
Add script command to script set to be run on each line of input |
-f sfile | --file=sfile |
Add script commands from file, one per line, to be run on each line of input script If there is only one script argument (no -e or -f options), the script can be an argument without a corresponding -e |
inputfile | - |
File(s) from which input is taken, operated on, concatenated, or output, a '-' or no input file specification indicates that sed's input comes from STDIN or a pipe |
Let's clarify the potential confusion over the options: -e script, -f sfile, and script. If there is more than one script or script file reference in a sed command, then all of the references must be qualified with either -e or -f as appropriate ('e' for script, 'f' for file). A single script command can be with or without a -e (or --expression=) prefix, as the author prefers.
# Good examples - legal invocations
1 sed -e script -f script -e script inputfile
2 sed script inputfile
3 sed -f sfile inputfile
# Bad examples - illegal calls
4 sed -f sfile script inputfile
5 sed script -e script inputfile
Confusingly, in the context of sed, a script is both a single [address]command (a notation we'll explain in just one moment - this is a chicken/egg problem) and a collection of scripts into a script file. In this description, we are talking about single sed scripts.
sed commands act on every input line, unless restricted to a subset of input by an optional prefixed address or range of addresses. Valid addresses are line numbers or regular expressions that can be matched against the input line. Address ranges are addresses separated by a single comma ',' without spaces. The following are valid addresses and address ranges, along with descriptions. Additionally, the $ character matches the last line of input.
18Matches line 18
/Regards/Matches any line that includes "Regards"
/[Ww]hich/Matches any line that includes "Which" or "which"
1,20Matches lines 1 through 20, inclusive
1,/Dear/Matches from line 1 through the first instance of "Dear"
/Dear/,$Matches from the first instance of "Dear" to end of input, through EOF either from file or input stream (STDIN)
/Dear/,/[Rr]egards/Matches from the first instance of "Dear" to the first instance of either "Regards" or "regards," inclusive
There is an address syntax N~Y, where N specifies the first line number to match, then also match every Yth line thereafter to the end of input. This is useful for paginating output, as we shall see in a later example. Also, a trailing '!' (exclamation point, referred to in *nix-speak as "Bang") on an address specification negates the address. That is: 15,20! means all lines except 15 through 20.
As briefly noted previously, addresses are optional. The effect is that a script without an address or range acts on every line of input. After the optional address, a command is needed. Table 18-2 describes the commands available for sed scripts, along with the address types to which each command applies. Commands that include spaces are enclosed in quotes (not shown in the table), to prevent shell expansion.
Table 18-2
sed Script Commands
| Command | Address Type | Description |
#comment |
None |
Comment extends until newline or to end of -e script fragment. |
} |
None |
Closing bracket for a command block. |
= |
None or 1 |
Output current line number. |
a \ |
None or 1 |
Append text to output, \ to embed newline characters. |
i \ |
None or 1 |
Insert text, \ to embed newline characters. |
q |
None or 1 |
Immediately exit sed, halt processing, output current pattern if -n not specified. |
r filename |
None or 1 |
Append text read from filename. |
{ |
None, 1, or range |
Begin block of commands. |
c \ |
None, 1, or range |
Replace selected lines with text, \ to embed newline characters. |
d |
None, 1, or range |
Delete pattern, input next line. |
h | H |
None, 1, or range |
Copy current input pattern to hold buffer. |
g | G |
None, 1, or range |
Copy hold buffer contents to current input pattern. |
x |
None, 1, or range |
Exchange hold buffer and input pattern. |
l |
None, 1, or range |
List out the current input pattern in "unambiguous" form. |
n | N |
None, 1, or range |
Append next input line onto current input pattern. |
p (lowercase) |
None, 1, or range |
Print current input pattern. (option with lowercase 'p') |
P |
None, 1, or range |
Print current input pattern up to first embedded newline (option with uppercase 'P') |
s/regex/replace/flags |
None, 1, or range |
Note: There's no real newline in this command, just table formatting. Perform substitution on current input pattern, put replace in for regex matched string. In replace, & repeats matched string, escaped \1 through \9 refer to matching sub-strings from the regex. flags can be g - match multiplen - substitute on nth matchp - print pattern if matchw - write to filename as below if matchI - case-insensitive match to regex |
w filename |
None, 1, or range |
Write current input pattern to filename. |
|
None, 1, or range |
Note: There's no real newline in this command, just table formatting. Transliteration from characters in source to characters in destination. Character counts must match. |
Putting addresses and commands together makes sed's initially steep learning curve somewhat . . . steeper, but there's a plateau just ahead. Let's look at some examples:
sed 's/^/ /' inputfile > outfile
This sed call has no address. The regex character code ^ matches the beginning of a line in the substitution. The function of this one-liner is to buffer every line of input four spaces to the right. The ">outfile" portion of the command uses the redirection symbol '>' to take the STDOUT stream (written to by sed), and instead write the data to outfile, overwriting outfile if it already exists.
sed /^#/d inputfile > outfile
This example above strips the stand-alone comment lines out of a file. It doesn't delete all the comments, just those full comment lines that start with a #. If the address had merely been specified as /#/, then every line with a # in it would have disappeared, including source lines with trailing comments, and quoted strings incorporating a #. In fact, this entire paragraph would be toast.
Another problem, of course, is how to search for characters that have special meaning (the metacharacters, like "/", "*", and others). Let's presume the existence of a file called c_header that has the following three lines in it:
/* A program header file: name and function */
/* Date: */
/* Author: */
You might have a file like this lying about your system; it's the header comment block for a bit of C code (distinctive because of the commenting characters pairs: "/*" and "*/"). Our goal now is to convert something like that into a header that can be used for shell scripts, where the comments start with a "#". This is done by using the backslash "\" to escape the metacharacters (or in other words, ignore their special meaning when preceded by a backslash):
[bilbrey@bobo bilbrey]$ sed 's/\/\*/#/' c_header
# A program header file: name and function */
# Date: */
# Author: */
The "/" and the "*" of the "/*" comment opening each are escaped separately, and now these lines are now fine comments for a script. Just redirect the output of the sed program to a new filename and Bob's your uncle.
One of the biggest hurdles we faced working up material to write about for this chapter was learning enough sed to be dangerous. Every reference, every online source, uses good interesting examples that make lots of sense, like the following:
sed 's/^[ \t]*//g' ifile > ofile
The preceding command is written to strip all of the leading whitespace (spaces and tabs) from the input file, leaving left justified lines written to ofile. The problem we were having? The script didn't work. In many other string and character-matching situations (especially the newer Perl language), \t is the typed stand-in for a tab character. This is a useful substitution, since the shell normally traps tabs in order to do command or filename completion. Likewise, the \n is the escaped control code for a newline.
Much hair was torn before our friend Moshe Bar, author of Linux Internals, gave us the necessary hint - in a script, actually type a tab. That solves the problem. The input data looks like this:
# Not indented
# Indented with tab
# Not indented
# Indented 2 spaces + tab
# Not indented
The script file reads simply:
#! /bin/sh
# lj - left justify input lines
sed 's/^[ ]*//g' $1
That simple three-line script (one working line following two comments) accomplishes the task. All five lines are left justified on output. When entered into a text processor, within the square brackets, type one space, and one tab. When the online resources start using samples that refer to \t, remember that this is used in called scripts only (not from the command line), and you must actually type the character you are searching on, not the escaped control sequence. Oh, and the newline character? Use \n when searching. Use an actual carriage return (escaped with a backslash) when substituting. Consistency is for wimps.
Here's an example of searching on a newline, then substituting, using an escaped actual carriage return. The search looks for "old" at the end of a line ($). If the pattern matches, the following actions are taken. The N command reads in a second input line, including an embedded newline. Then a substitution command is called, including the embedded newline. If the first part of the sub is matched the replacement is inserted, starting with a newline (backslash followed by Enter), then the phrase "Young Turks"
/Old$/{
N
s/Old\nMen/\
Young Turks/
}
We have only shown you a small fraction of sed's capabilities. In fairness, we note that there are several versions of sed loose in the world. What we have described here works in most of these variations. There are a variety of resources for learning sed as well, from a few books to many online tutorials. Script examples that work for one version of sed do not work for another, and sed documentation is woefully cryptic and incomplete.
However, no mention of scripting is complete without referring to sed. We have done our duty, and sincerely hope that we haven't confused you too much. Now, let's have a look at the GNU implementation of awk.
gawkThe GNU Project's gawk (currently version 3.03) is the implementation of awk that comes with OpenLinux (and most other Linux distributions). Awk and its offspring operate by searching files for patterns, and performing actions on input lines or fields that match the search pattern. Here is gawk's command line usage:
gawk - Pattern scanning and processing language
Usage : gawk [options] -f progfile... [--] inputfile ...
|
|
-F fs |
Use the character or expression fs as a input field separator |
-v | --assign var=val |
Preset value (val) into variable (var) for use during input processing |
--traditional |
Run in compatibility mode, don't use GNU extensions. |
--copyleft |
Print short form GNU copyright message then exit |
--lint |
Warn about non-portable program usage (especially GNU extensions not used in other awk implementations) |
--lint-old |
Warn about any usage not compatible with original Unix awk definition |
--posix |
Like --traditional, with additional restrictions |
--re-interval |
Enables interval expressions in regex's. Non-standard but POSIX compliant behavior likely to break old awk scripts |
--source prog-text |
Another method to specify prog-text to be used in processing, allows in-line program text to be mixed with -f prog-file awk programs |
prog-text |
In-line awk program instructions |
inputfile | - |
File(s) from which input is taken, operated on, concatenated, or output, a '-' or no input file specification indicates that sed's input comes from STDIN or a pipe |
gawk input comes either from files specified on the command line, or from the STDIN stream. Actions to be performed upon the input data are in form of patterns (regular expressions) matched with action statements (or defined functions, which are grouped actions). These pattern:action statements are typed in gawk program files, or on the command line. Functions are defined in gawk program files.
When invoked, gawk first completes any command line specified variable assignments. Program sources (file and command line) are concatenated, then compiled into an internal form for both error checking and speed of execution. Finally, the input files (if referenced on the command line) or standard input are processed.
There are a variety of other controllable features of gawk, such as environment variables, that are not included in this discussion. Additionally, we do not cover all of the command and pattern:action forms that are available in this powerful language. To view the online documentation with your OpenLinux system, type info gawk or man gawk.
Input files are logically broken up into records, with the newline character as a record separator. Fields within each record are separated by the fs (the field separator). A good example of the type of file which can easily be broken up into records and fields is the password file, /etc/passwd.
* * *
httpd:x:55:55:HTTP Server:/:/bin/false
nobody:x:65534:65534:Nobody:/:/bin/false
syroid:x:500:100:Tom Syroid:/home/syroid:/bin/bash
bilbrey:x:501:100:Brian Bilbrey:/home/bilbrey:/bin/bash
The preceding fragment shows that each line in the password file contains an ordered, logical set of fields. This will be a good sample data set for use in demonstrating a few of the features of gawk. First, look at the data to be parsed and processed. The field separator in this case is a ':'. There are seven distinct fields within each record. Learn more about the data and structure of the password file by typing man 5 passwd. These fields are addressed in the pattern:action statements as $1 through $7. $0 refers to the entire input record (line).
[syroid@janus syroid]$ awk -F: '/home/ {print $5,"\t"$6}' /etc/passwd
FTP User, /home/ftp
Postgres User, /home/postgres
Tom Syroid, /home/syroid
Brian Bilbrey, /home/bilbrey
The preceding example searches the whole of each input line to match the string "home" (marked as a regular expression by the forward slashes). If there is a match, then the action is performed. The requested action is to print the fifth field (User Name), followed by a comma, a tab (encased in double quotes for expansion), and finally the home directory (field 6) of the user. Whew. As Tom would say, take a deep breath.
More on Sed and Awk (Gawk)
On OpenLinux
From the command line, typeman sedandman gawk, respectively.Online
The University of Utah has a good manual for gawk at http://www.cs.utah.edu/dept/old/texinfo/gawk/gawk_toc.html. The sed FAQ is also most helpful, located at http://www.dreamwvr.com/sed-info/sed-faq.html.Printed Matter
sed & awk, 2nd Edition, Dale Dougherty and Arnold Robbins (O'Reilly and Associates).
In preparation for writing these few short pages about Perl, we open three references printed on dead trees, three online resources, and the Perl overview manpage. Overkill? Perhaps, but Perl is like that. Perl is a scripting language with an incredibly wide range of applications, from system scripts for installing software, to CGI scripts that execute on some of the most heavily trafficked sites on the Internet. Unlike other scripting languages, Perl is very rarely executed on the command line. Anything that could be done in Perl on the command line is trivial enough that one of the other scripting languages is usually sufficient.
Larry Wall, hacker and all-around interesting guy, wrote Perl as a tool to get coherent reports from a complex hierarchy of files, since awk wasn't up to the task. Formally, Perl stands for "Practical Extraction and Report Language." When he believes that no one is listening, Larry calls it a "Pathologically Eclectic Rubbish Lister."
Several seemingly contradictory facts are true about Perl:
That said, there are roughly a thousand pages of documentation on your OpenLinux system, installed along with Perl. There are hundreds of sites on the Internet that address the various needs of the Perl programming community. There are Usenet newsgroups and several good books. Having dipped our toes into this pool on a couple of occasions, our conclusion is that Perl is not so much a scripting language as a lifestyle. That said, we'll happily address the former for a short while.
This section is subtitled: "Meet Perl in a dark back alley on a foggy night!" Confirm that Perl is loaded in your system by typing perl --version. The version number should be over 5 for most recent GNU/Linux distributions.
The first sample program is a simple one-liner (well, three, but you get the picture). The line numbers, as usual, are present for reference only. Don't type them into your scripts:
1 #!/usr/bin/perl -w
2 print ("Hello, cruel world!\n");
3
The first line, like that found in shell scripts, is the magic invocation of the environment in which to execute the following script. Here, of course, we find Perl, with the -w option enabled so that useful error messages have a chance of printing when a typing error is made. Note that like sed and shell scripts, Perl requires that the last line be terminated with a newline. Save the file under the name hello, make it executable by typing chmod 755 hello, (permission mode 755 is user rwx, and group/world rx), then test it:
[syroid@janus syroid]$ ./hello
Hello, cruel world!
Although the example is fairly simple, several features of Perl are present. First, the function to display data to STDOUT is called print. Strings are quoted with double quotes. Lastly, every Perl command line terminates with a semicolon.
Well, there are exceptions to the semicolon rule, but they are irrelevant: just follow the rule. When you forget, if you remembered to put that -w on the first line, then Perl will do its best to help you figure out where the semicolons should be.
Here's another sample program, this time with input and output, as well as some control structures:
1 #!/usr/bin/perl -w
2 # file: getage
3
4 print "What's your name? ";
5 $Name = <STDIN>;
6 chomp ($Name);
7 print "How old are you? ";
8 $Age = <STDIN>;
9 chomp ($Age);
10 if ($Name eq "Tom") {
11 print "Tom! Good to see you. Looking younger every day!\n";
12 } else {
13 print "Sheesh. $Age? $Name, you're older than dirt!\n";
14 }
15
One of the major advantages of writing Perl code (for some part of the world's population, anyway) is that it can be written in this language that's very nearly, but weirdly different from, English. Of course, there are bits of standard programming language accessories, like brackets to mark logical blocks of code. Then Larry's sense of humor gave us commands like chomp, which is a function to remove the trailing newline character from user input. In operation, the previous script displays output as follows:
[syroid@janus syroid]$ ./getage
What's your name? Brian
How old are you? 39
Sheesh. 39? Brian, you're older than dirt!
The unofficial motto of Perl programmers is "There Is More than One Way to Do It." In keeping with this statement, there are over 100 print books featuring Perl as a primary topic, as well as countless online faqs (Frequently Asked Questions), tutorials, explanations, and so on. Perl is generally used in situations where a few lines of shell script isn't up to a task, and writing a C program will take too long. There are many paths to learning Perl.
Lastly, CPAN (Comprehensive Perl Archive Network) has more than 800MB of Perl resources available, including modules and libraries to accomplish virtually any chore. Once you learn enough Perl to be functional, survey CPAN before you go about reinventing the wheel, FM radio, and cruise control.
More Perl Resources
On OpenLinux
From the command line, typeman perl. There are many manual pages for various aspects of Perl - the main Perl manpage is simply a directory and overview.Online
The source of all things Perl is at http://www.perl.com/.Printed Matter
Learning Perl, 2nd Edition, Randal Schwartz and Tom Christiansen (O'Reilly and Associates).
Tcl is the abbreviation for Tool Control Language. Tcl is designed to be used as glue logic to connect various pieces of more complex code, whether interactive programs or special purpose C programs. Tcl is a language, as well as the library that implements the functionality. Most documentation (including this section) blurs the distinction between language and library.
Tk is the "Tool Kit" that provides an X-Window (graphical) interface for Tcl. Tcl/Tk is a deceptively simple, yet powerful scripting and RAD (Rapid Application Development) environment. Dr. John Ousterhout wrote the first versions of these programs in the late 1980s while at the University of California at Berkeley.
Why address GUI scripting while we are deep in the midst of command-line utilities, features, and functions? Well, Tcl/Tk is the remaining "major" scripting environment in Linux; it is appropriate that we finish out our treatment of the topic here. Additionally, Tcl/Tk is frequently used to GUI-ize command line programs.
Users typically interact with Tcl/Tk via wish, a windowing shell that provides an environment for prototyping and running Tcl/Tk applications.
wish - Simple windowing shell
Usage : wish [filename] [option...]
|
|
-colormap new |
Window created using new colormap |
-display disp |
Create window on specified X display and screen, for example, specify one of two X servers running at :0 and :1 |
-geometry geometry |
set geometry global variable to store window dimensions |
-name title |
Use title as window title, and name to address window in send commands, use double quotes for multi-word titles |
See the wish manual page for more information about startup options. Like most of the other scripting environments discussed in this chapter, wish can be invoked from the command line. Also it can be used inside a script, as we shall see shortly.
Start wish from the command line (in a virtual terminal in X), to create a new window on the desktop. In the command line terminal, a % prompt is displayed - this is where you interact with the wish shell to create an interface. Commands submitted to wish via the % prompt are executed in the window(s) created. Here's a sample wish session:
[syroid@janus syroid]$ wish -name "Syroid's Window" % button .b -text "Hello Cruel World" -command exit .b % button .c -text "Make Coffee" -command exit .c % button .d -text "Eat Chocolate" -command exit .d % pack .b .c .d
As each button is declared, it is named (.b, .c, and .d, respectively), titled, and associated with a command. The command can be either a Tcl built-in function, or a user/library function that has been pre-defined. In this case, we used the "exit" function with all three buttons. The pack command submits the named buttons to the window. When this is executed, the window is resized to fit the buttons exactly. In Figure 18-1 below, we stretched the window out after the fact to show the full title. Clicking on any one of the buttons terminates the "application" that has been written, and ends the wish session in the calling terminal at the same time.
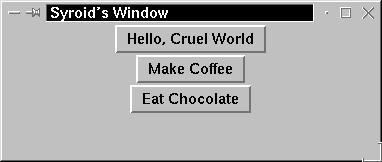
Figure 18-1
A window with three buttons, defined in the Tcl/Tk wish environment
Like the other scripting languages discussed in this chapter, Tcl/Tk has only limited utility on the command line. In scripts, the power of this environment quickly becomes evident. The help system for Tcl/Tk is a graphical interface to the large number of manual pages for the various functions written in Tcl/Tk. Here's a chunk of the tclhelp code, written by Karl Lehenbauer and Mark Diekhans.
#------------------------------------------------
# Create a frame to hold buttons for the specified list of either help files
# or directories.
proc ButtonFrame {w title subject fileList} {
frame $w
label $w.label -relief flat -text $title -background SlateGray1
pack $w.label -side top -fill both
frame $w.buttons
pack $w.buttons -side top -expand 1 -anchor w
set col 0
set row 0
while {![lempty $fileList]} {
AddButton $w.buttons $subject [lvarpop fileList] $row $col
if {[incr col] >= 5} {
incr row
set col 0
}
}
}
We aren't going to explain the ins and outs of programming in Tcl/Tk, due to lack of space, time and deep expertise. Observe that unlike some other program code that we have seen (but rather like Perl), this is quite like English in syntax. Overall, the program code that comprises the tclhelp application is only 431 lines of code in the style of the previous procedure. It generates a tiered multi-window application, including the /tk/widgets help window in Figure 18-2.
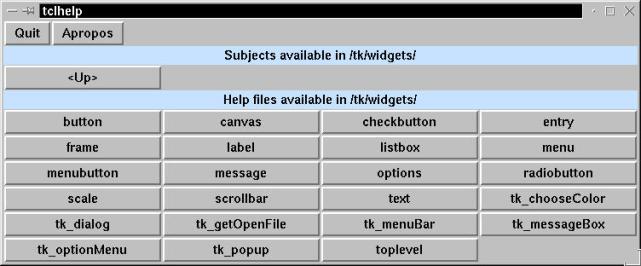
Figure 18-2
tclhelp window showing the various widgets (tools) available in TK.
Tcl/Tk is used to write graphical front-ends for command line utilities. It is the conceptual precursor to more recent graphical window control and widget libraries, such as Qt and GTK. (Qt is the library underlying the KDE environment; GTK is the GIMP Tool Kit, which is the basis of the Gnome Desktop.
Tcl/Tk Resources
On OpenLinux
From the command line, typetclhelp.Online
An Introduction to Programming with Tcl can be found at http://hegel.ittc.ukans.edu/topics/tcltk/tutorial-noplugin.html. Another good online introduction for Tcl/Tk is at the Linux Documentation Project: http://www.linuxdoc.org/HOWTO/TclTk-HOWTO.html.Printed Matter
Tcl and the Tk Toolkit, John Ousterhout, Addison-Wesley
Tcl/Tk for Dummies, Tim Webster and Alex Francis, IDG Books Worldwide
Scripts are (usually) short programs for accomplishing tasks using Linux. There are a variety of scripting languages. Conceptually similar to batch languages available in other operating systems, scripting is a powerful way of bridging the functionality gap between command-line operation and full programming languages such as C.
This chapter covered the following points:
Go to the Table Of Contents