Chapter 2
The Internet and the World Wide Web
The Internet
The Internet and the World Wide Web are two of the principal building blocks
that are used in the development of digital libraries. This chapter describes
their main features. It also discusses the communities of engineers and computer
scientists who created and continue to develop them. In contrast, the next chapter
focuses on librarians, publishers, and other information professionals. Each
chapter includes a discussion of how the community functions, its sense of purpose,
the social conventions, priorities, and some of the major achievements.
As its name suggest, the Internet is not a single homogeneous network. It is
an interconnected group of independently managed networks. Each network supports
the technical standards needed for inter-connection - the TCP/IP family of protocols
and a common method for identifying computers - but in many ways the separate
networks are very different. The various sections of the Internet use almost
every kind of communications channel that can transmit data. They range from
fast and reliable to slow and erratic. They are privately owned or operated
as public utilities. They are paid for in different ways. The Internet is sometimes
called an information highway. A better comparison would be the international
transportation system, with everything from airlines to dirt tracks.
Historically, these networks originated in two ways. One line of development
was the local area networks that were created to link computers and terminals
within a department or an organization. Many of the original concepts came from
Xerox's Palo Alto Research Center. In the United States, universities were pioneers
in expanding small local networks into campus-wide networks. The second source
of network developments were the national networks, known as wide area networks.
The best known of these was the ARPAnet, which, by the mid-1980s, linked about
150 computer science research organizations. In addition, there were other major
networks, which have been almost forgotten, such as Bitnet in the United States.
Their users are now served by the Internet.
Since the early networks used differing technical approaches, linking them
together was hard. During the late 1980s the universities and the research communities
converged on TCP/IP, the protocols of the ARPAnet, to create the Internet that
we know today. A key event was the 1986 decision by the National Science Foundation
to build a high-speed network backbone for the United States and to support
the development of regional networks connected to it. For this backbone, the
foundation decided to build upon the ARPAnet's technical achievements and thus
set the standards for the Internet. Meanwhile, campus networks were using the
same standards. We built one of the first high-speed networks at Carnegie Mellon,
completing the installation in 1986. It accommodated several methods of data
transmission, and supported competing network protocols from Digital, Apple,
and IBM, but the unifying theme was the use of TCP/IP.
Future historians can argue over the combination of financial, organizational,
and technical factors that led to the acceptance of the ARPAnet technical standards.
Several companies made major contributions to the development and expansion
of the Internet, but the leadership came from two U.S. government organizations:
DARPA and the National Science Foundation. Chapter 4 describes the contribution
that these organizations continue to make to digital libraries research.
An introduction to Internet technology
The technology of the Internet is the subject of whole books. Most of the details
are unimportant to users, but a basic understanding of the technology is useful
when designing and using digital libraries. Panel 2.1 is a brief introduction
to TCP/IP, the underlying protocols that define the Internet.
|
Panel 2.1
An introduction to TCP/IP
The two basic protocols that hold the Internet together
are known as TCP/IP. The initials TCP and IP are joined together so often
that it is easy to forget that they are two separate protocols.
IP
IP, the Internet Protocol, joins together the separate
network segments that constitute the Internet. Every computer on the Internet
has a unique address, known as an IP address. The address consists of
four numbers, each in the range 0 to 255, such as 132.151.3.90. Within
a computer these are stored as four bytes. When printed, the convention
is to separate them with periods as in this example. IP, the Internet
Protocol, enables any computer on the Internet to dispatch a message to
any other, using the IP address. The various parts of the Internet are
connected by specialized computers, known as "routers". As their
name implies, routers use the IP address to route each message on the
next stage of the journey to its destination.
Messages on the Internet are transmitted as short packets,
typically a few hundred bytes in length. A router simply receives a packet
from one segment of the network and dispatches it on its way. An IP router
has no way of knowing whether the packet ever reaches its ultimate destination.
TCP
Users of the network are rarely interested in individual
packets or network segments. They need reliable delivery of complete messages
from one computer to another. This is the function of TCP, the Transport
Control Protocol. On the sending computer, an application program passes
a message to the local TCP software. TCP takes the message, divides it
into packets, labels each with the destination IP address and a sequence
number, and sends them out on the network. At the receiving computer,
each packet is acknowledged when received. The packets are reassembled
into a single message and handed over to an application program.
This protocol should be invisible to the user of a digital
library, but the responsiveness of the network is greatly influenced by
the protocol and this often affects the performance that users see. Not
all packets arrive successfully. A router that is overloaded may simply
ignore some packets. This is called, "dropping a packet." If
this happens, the sending computer never receives an acknowledgment. Eventually
it gets tired of waiting and sends the packet again. This is known as
a "time-out" and may be perceived by the user as an annoying
delay.
Other protocols
TCP guarantees error-free delivery of messages, but it
does not guarantee that they will be delivered punctually. Sometimes,
punctuality is more important than complete accuracy. Suppose one computer
is transmitting a stream of audio that another is playing immediately
on arrival. If an occasional packet fails to arrive on time, the human
ear would much prefer to lose tiny sections of the sound track rather
than wait for a missing packet to be retransmitted, which would be horribly
jerky. Since TCP is unsuitable for such applications, they use an alternate
protocol, named UDP, which also runs over IP. With UDP, the sending computer
sends out a sequence of packets, hoping that they will arrive. The protocol
does its best, but makes no guarantee that any packets ever arrive.
|
Panel 2.1 introduced the Internet addresses, known as IP addresses. Another
way to identify a computer on the Internet is to give it a name such as tulip.mercury.cmu.edu.
Names of this form are known as domain names and the system that relates
domain names to IP addresses is known as the domain name system or DNS.
Domain names and their role in digital libraries are studied in Chapter 12.
Computers that supports the TCP/IP protocols usually provide a standard set
of basic applications. These applications are known as the TCP/IP suite. Some
of the most commonly used are listed in Panel 2.2.
|
Panel 2.2
The TCP/IP suite
The TCP/IP suite is a group of computer programs, based
on TCP/IP, that are provided by most modern computers. They include the
following.
Terminal emulation. Telnet is a
program that allows a personal computer to emulate an old-fashioned computer
terminal that has no processing power of its own but relies on a remote
computer for processing. Since it provides a lowest common denominator
of user interface, telnet is frequently used for system administration.
File transfer. The basic protocol
for moving files from one computer to another across the Internet is FTP
(the file transfer protocol). Since FTP was designed to make use of TCP
it is an effective way to move large files across the Internet.
Electronic mail. Internet mail uses a protocol known
as Simple Mail Transport Protocol (SMTP). This is the protocol that turned
electronic mail from a collection of local services to a single, world-wide
service. It provides a basic mechanism for delivering mail. In recent
years, a series of extensions have been made to allow messages to include
wider character sets, permit multi-media mail, and support the attachment
of files to mail messages.
|
The Internet community
The technology of the Internet is important, but the details of the technology
may be less important than the community of people who developed it and continue
to enhance it. The Internet pioneered the concept of open standards. In 1997,
Vinton Cerf and Robert Kahn received the National Medal of Technology for their
contributions to the Internet. The citation praised their work on the TCP/IP
family of protocols, but it also noted that they, "pioneered not just a
technology, but also an economical and efficient way to transfer that technology.
They steadfastly maintained that their internetworking protocols would be freely
available to anyone. TCP/IP was deliberately designed to be vendor-independent
to support networking across all lines of computers and all forms of transmission."
The Internet tradition emphasizes collaboration and, even now, the continuing
development of the Internet remains firmly in the hands of engineers. Some people
seem unable to accept that the U.S. government is capable of anything worthwhile,
but the creation of the Internet was led by government agencies, often against
strong resistance by companies who now profit from its success. Recently, attempts
have been made to rewrite the history of the Internet to advance vested interest,
and for individuals to claim responsibility for achievements that many shared.
The contrast is striking between the coherence of the Internet, led by far-sighted
government officials, and the mess of incompatible standards in areas left to
commercial competition, such as mobile telephones.
An important characteristic of the Internet is that the engineers and computer
scientists who develop and operate it are heavy users of their own technology.
They communicate by e-mail, dismissing conventional mail as "snail mail."
When they write a paper they compose it at their own computer. If it is a web
page, they insert the mark-up tags themselves, rather than use a formatting
program. Senior computer scientists may spend more time preparing public presentations
than writing computer programs, but programming is the basic skill that everybody
is expected to have.
|
Panel 2.3
NetNews or Usenet
The NetNews bulletin boards, also known as Usenet, are
an important and revealing examples of the Internet community's approach
to the open distribution of information. Thousands of bulletin boards,
called news groups, are organized in a series of hierarchies. The highest
level groupings include "comp", for computer-related information,
"rec" for recreational information, the notorious "alt"
group, and many more. Thus "rec.arts.theatre.musicals" is a
bulletin board for discussing musicals. (The British spelling of "theatre"
suggests the origin of this news group.)
The NetNews system is so decentralized that nobody has
a comprehensive list of all the news groups. An individual who wishes
to post a message to a group sends it to the local news host. This passes
it to its neighbors, who pass it to their neighbors and so on.
If we consider a digital library to contain managed information,
NetNews is the exact opposite. It is totally unmanaged information. There
are essentially no restrictions on who can post or what they can post.
At its worst the system distributes libel, hate, pornography, and simply
wrong information, but many news groups work remarkably well. For example,
people around the world who use the Python programming language have a
news group, "comp.lang.python", where they exchange technical
information, pose queries, and communicate with the developer.
|
Scientific publishing on the Internet
The publishing of serious academic materials on the Internet goes back many
years. Panels 2.4 and 2.5 describe two important examples, the Internet RFC
series and the Physics E-Print Archives at the Los Alamos National Laboratory.
Both are poorly named. The letters "RFC" once stood for "Request
for Comment", but the RFC series is now the definitive technical series
for the Internet. It includes a variety of technical information and the formal
Internet standards. The Los Alamos service is not an archive in the usual sense.
Its primary function is as a pre-print server, a site where researchers can
publish research as soon as it is complete, without the delays of conventional
journal publishing.
Whatever the merits of their names, these two services are of fundamental importance
for publishing research in their respective fields. They are important also
because they demonstrate that the best uses of digital libraries may be new
ways of doing things. One of the articles of faith within scholarly publishing
is that quality can be achieved only by peer review, the process by which every
article is read by other specialists before publication. The process by which
Internet drafts become RFCs is an intense form of peer review, but it takes
place after a draft of the paper has been officially posted. The Los Alamos
service has no review process. Yet both have proved to be highly effective methods
of scientific communication.
Economically they are also interesting. Both services are completely open to
the user. They are professionally run with substantial budgets, but no charges
are made for authors who provide information to the service or to readers who
access the information. Chapter 6 looks more deeply at the economic models behind
the services and the implications for other scientific publishing.
The services were both well-established before the emergence of the web. The
web has been so successful that many people forget that there are other effective
ways to distribute information on the Internet. Both the Los Alamos archives
and the RFC series now use web methods, but they were originally built on electronic
mail and file transfer.
|
Panel 2.4
The Internet Engineering Task Force and the RFC series
The Internet Engineering Task Force
The Internet Engineering Task Force (IETF) is the body
that coordinates technical aspects of the Internet. Its methods of working
are unique, yet it has proved extraordinarily able to get large numbers
of people, many from competing companies, to work together. The first
unusual feature is that the IETF is open to everybody. Anybody can go
to the regular meetings, join the working groups, and vote.
The basic principle of operation is "rough consensus
and working code". Anybody who wishes to propose a new protocol or
other technical advance is encouraged to provide a technical paper, called
an Internet Draft, and a reference implementation of the concept. The
reference implementation should be software that is openly available to
all. At the working group meetings, the Internet Drafts are discussed.
If there is a consensus to go ahead, then they can join the RFC standards
track. No draft standard can become a formal standard until there are
implementations of the specification, usually computer programs, openly
available for everybody to use.
The IETF began in the United States, but now acts internationally.
Every year, one meeting is outside the U.S.. The participants, including
the working group leaders, come from around the world. The IETF was originally
funded by U.S. government grants, but it is now self-sufficient. The costs
are covered by meeting fees.
The IETF as a community
The processes of the IETF are open to everybody who wishes
to contribute. Unlike some other standards bodies, whose working drafts
are hard to obtain and whose final standards are complex and expensive,
all Internet Drafts and RFCs are openly available. Because of the emphasis
on working software, when there is rivalry between two technical approaches,
the first to be demonstrated with software that actually works has a high
chance of acceptance. As a result, the core Internet standards are remarkably
simple.
In recent years, IETF meetings have grown to more than
two thousand people, but, because they divide into working groups interested
in specific topics, the basic feeling of intimacy remains. Almost everybody
is a practicing engineer or computer scientists. The managers stay at
home. The formal meetings are short and informal; the informal meetings
are long and intense. Many an important specification came from a late
evening session at the IETF, with people from competing organizations
working together.
Because of its rapid growth, the Internet is in continually
danger of breaking down technically. The IETF is the fundamental reason
that it shows so much resilience. If a single company controlled the Internet,
the technology would be as good as the company's senior engineering staff.
Because the IETF looks after the Internet technology, whenever challenges
are anticipated, the world's best engineers combine to solve them.
Internet Drafts
Internet Drafts are a remarkable series of technical
publications. In science and engineering, most information goes out of
date rapidly, but journals sit on library shelves for ever. Internet Drafts
are the opposite. Each begins with a fixed statement that includes the
words:
"Internet-Drafts are draft documents valid for a
maximum of six months and may be updated, replaced, or obsoleted by other
documents at any time. It is inappropriate to use Internet-Drafts as reference
material or to cite them other than as work in progress."
The IETF posts online every Internet Draft that is submitted,
and notifies interested people through mailing lists. Then the review
begins. Individuals post their comments on the relevant mailing list.
Comments range from detailed suggestions to biting criticism. By the time
that the working group comes to discuss a proposal, it has been subjected
to public review by the experts in the field.
The RFC series
The RFC series are the official publications of the IETF.
These few thousand publications form a series that goes back almost thirty
years. They are the heart of the documentation of the Internet. The best
known RFCs are the standards track. They include the formal specification
of each version of the IP protocol, Internet mail, components of the World
Wide Web, and many more. Other types of RFC include informational RFCs,
which publish technical information relevant to the Internet.
Discussions of scientific publishing rarely mention the
RFC series, yet it is hard to find another set of scientific or engineering
publications that are so heavily reviewed before publication, or are so
widely read by the experts in the field. RFCs have never been published
on paper. Originally they were available over the Internet by FTP, more
recently by the web, but they still have a basic text-only format, so
that everybody can read them whatever computing system they use.
|
|
Panel 2.5
The Los Alamos E-Print Archives
The Physics E-print Archives are an intriguing example
of practicing scientists taking advantage of the Internet technology to
create a new form of scientific communication. They use the Internet to
extend the custom of circulating pre-prints of research papers. The first
archive was established in1991, by Paul Ginsparg of Los Alamos National
Laboratory, to serve the needs of a group of high-energy physicists. Subsequent
archives were created for other branches of physics, mathematics, and
related disciplines. In 1996, Ginsparg reported, "These archives
now serve over 35,000 users worldwide from over 70 countries, and process
more than 70,000 electronic transactions per day. In some fields of physics,
they have already supplanted traditional research journals as conveyers
of both topical and archival research information."
The operation of the archives
The primary function of the archives is for scientists
to present research results. Frequently, but not always, these are papers
that will be published in traditional journals later. Papers for the archives
are prepared in the usual manner. Many physicists use the TeX format,
which has particularly good support for mathematics, but other formats,
such as PostScript, or HMTL are also used. Graphs and data can be embedded
in the text or provided as separate files.
The actual submission of a paper to an archive can be
by electronic mail, file transfer using the FTP protocol, or via a web
form. In each case, the author provides the paper, a short abstract, and
a standard set of indexing metadata. Processing by the archive is entirely
automatic. The archives provide a search service based on electronic mail,
a web-based search system, and a notification service to subscribers,
which also uses electronic mail. The search options include searching
one or many of the archives. Readers can search by author and title, or
search the full text of the abstracts.
As this brief description shows, the technology of the
archives is straightforward. They use the standard formats, protocols,
and networking tools that researchers know and understand. The user interfaces
have been designed to minimize the effort required to maintain the archive.
Authors and readers are expected to assist by installing appropriate software
on their own computers, and by following the specified procedures.
The economic model
This is an open access system. The cost of maintaining
the service is funded through annual grants from the National Science
Foundation and the Department of Energy. Authors retain copyright in their
papers. Indeed, about the only mention of copyright in the archive instructions
is buried in a page of disclaimers and acknowledgments.
As Ginsparg writes, "Many of the lessons learned
from these systems should carry over to other fields of scholarly publication,
i.e. those wherein authors are writing not for direct financial remuneration
in the form of royalties, but rather primarily to communicate information
(for the advancement of knowledge, with attendant benefits to their careers
and professional reputations)."
|
The World Wide Web
The World Wide Web, or "the web" as it is colloquially called,
has been one of the great successes in the history of computing. It ranks with
the development of word processors and spread sheets as a definitive application
of computing. The web and its associated technology have been crucial to the
rapid growth of digital libraries. This section gives a basic overview of the
web and its underlying technology. More details of specific aspects are spread
throughout the book.
The web is a linked collection of information on many computers on the Internet
around the world. These computers are called web servers. Some of web servers
and the information on them are maintained by individuals, some by small groups,
perhaps at universities and research centers, others are large corporate information
services. Some sites are consciously organized as digital libraries. Other excellent
sites are managed by people who would not consider themselves librarians or
publishers. Some web servers have substantial collections of high-quality information.
Others are used for short term or private purposes, are informally managed,
or are used for purposes such as marketing that are outside the scope of libraries.
The web technology was developed about 1990 by Tim Berners-Lee and colleagues
at CERN, the European research center for high-energy physics in Switzerland.
It was made popular by the creation of a user interface, known as Mosaic, which
was developed by Marc Andreessen and others at the University of Illinois, Urbana-Champaign.
Mosaic was released in 1993. Within a few years, numerous commercial versions
of Mosaic followed. The most widely used are the Netscape Navigator and Microsoft's
Internet Explorer. These user interfaces are called web browsers, or
simply browsers.
The basic reason for the success of the web can be summarized succinctly. It
provides a convenient way to distribute information over the Internet. Individuals
can publish information and users can access that information by themselves,
with no training and no help from outsiders. A small amount of computer knowledge
is needed to establish a web site. Next to none is needed to use a browser to
access the information.
The introduction of the web was a grass roots phenomenon. Not only is the technology
simple, the manner in which it was released to the public avoided almost all
barriers to its use. Carnegie Mellon's experience was typical. Individuals copied
the web software over the Internet onto private computers. They loaded information
that interested them and made it accessible to others. Their computers were
already connected to the campus network and hence to the Internet. Within six
months of the first release of Mosaic, three individuals had established major
collections of academic information, covering statistics, English, and environmental
studies. Since the Internet covers the world, huge numbers of people had immediate
access to this information. Subsequently, the university adopted the web officially,
with a carefully designed home page and information about the university, but
only after individuals had shown the way.
One reason that individuals have been able to experiment with the web is that
web software has always been available at no charge over the Internet. CERN
and the University of Illinois set the tradition with open distribution of their
software for web servers and user interfaces. The most widely used web servers
today is a no-cost version of the Illinois web server, known as Apache. The
availability of software that is distributed openly over the Internet provides
a great stimulus in gaining acceptance for new technology. Most technical people
enjoy experimentation but dislike bureaucracy. The joy goes out of an experiment
if they need to issue a purchase order or ask a manager to sign a software license.
Another reason for the instant success of the web was that the technology provides
gateways to information that was not created specifically for the web. The browsers
are designed around the web protocol called HTTP, but the browsers also support
other Internet protocols, such as file transfer (FTP), Net News, and electronic
mail. Support for Gopher and WAIS, two other protocols which are now almost
obsolete, allowed earlier collections of information to coexist with the first
web sites. Another mechanism, the Common Gateway Interface (CGI), allows browsers
to bridge the gap between the web and any other system for storing online information.
In this way, large amounts of information were available as soon as Mosaic became
available.
From the first release of Mosaic, the leading browsers have been available
for the most common types of computer - the various versions of Windows, Macintosh
and Unix - and browsers are now provided for all standard computers. The administrator
of a web site can be confident that users around the world will see the information
provided on the site in roughly the same format, whatever computers they have.
The technology of the web
Technically, the web is based on four simple techniques. They are: the Hyper-Text
Mark-up Language (HTML), the Hyper-Text Transport Protocol (HTTP), MIME data
types, and Uniform Resource Locators (URLs). Each of these concepts is introduced
below and discussed further in later chapters. Each has importance that goes
beyond the web into the general field of interoperability of digital libraries.
HTML
HTML is a language for describing the structure and appearance of text documents.
Panel 2.6 shows a simple HTML file and how a typical browser might display,
or render, it.
|
Panel 2.6
An HTML example
An HTML file
Here is a simple text file in HTML format as it would
be stored in a computer. It shows the use of tags to define the structure
and format of a document.
|
<html>
<head>
<title>D-Lib</title>
</head>
<body>
<h1>D-Lib Magazine</h1>
<img src = "logo.gif">
<p>Since the first issue appeared in July
1995,
<a href = "http://www.dlib.org/dlib.html">D-Lib
Magazine</a> has appeared monthly as a compendium of research,
news, and progress in digital libraries.</p>
<p><i>William Y. Arms
<br>January 1, 1999</i></p>
</body>
</html>
|
The document displayed by a web browser
When displayed by a browser, this document might be rendered
as follows. The exact format depends upon the specific browser, computer,
and choice of options.
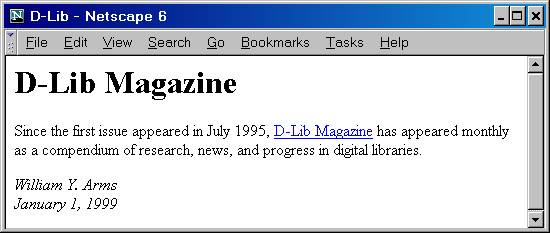
|
As this example shows, the HTML file contains both the text to be rendered
and codes, known as tags, that describe the format or structure. The HMTL tags
can always be recognized by the angle brackets (< and >). Most HTML tags
are in pairs with a "/" indicating the end of a pair. Thus <title>
and </title> enclose some text that is interpreted as a title. Some of
the HTML tags show format; thus <i> and </i> enclose text to be
rendered in italic, and <br> shows a line break. Other tags show structure:
<p> and </p> delimit a paragraph, and <h1> and </h1>
bracket a level one heading. Structural tags do not specify the format, which
is left to the browser.
For example, many browsers show the beginning of a paragraph by inserting a
blank line, but this is a stylistic convention determined by the browser. This
example also shows two features that are special to HMTL and have been vital
to the success of the web. The first special feature is the ease of including
color image in web pages. The tag:
<img src = "logo.gif">
is an instruction to insert an image that is stored in a separate file. The
abbreviation "img" stands for "image" and "src"
for "source". The string that follows is the name of the file in which
the image is stored. The introduction of this simple command by Mosaic brought
color images to the Internet. Before the web, Internet applications were drab.
Common applications used unformatted text with no images. The web was the first,
widely used system to combine formatted text and color images. Suddenly the
Internet came alive.
The second and even more important feature is the use of hyperlinks. Web pages
do not stand alone. They can link to other pages anywhere on the Internet. In
this example, there is one hyperlink, the tag:
<a href = "http://www.dlib.org/dlib.html">
This tag is followed by a string of text terminated by </a>. When displayed
by as browser, as in the panel, the text string is highlighted; usually it is
printed in blue and underlined. The convention is simple. If something is underlined
in blue, the user can click on it and the hyperlink will be executed. This convention
is easy for the both the user and the creator of the web page. In this example,
the link is to an HTML page on another computer, the home page of D-Lib Magazine.
The basic concepts of HTML can be described in a short tutorial and absorbed
quickly, but even simple tagging can create an attractive document. In the early
days of the web, everybody was self-taught. A useful characteristic of HTML
is that its syntax is forgiving of small mistakes. Other computing languages
have strict syntax. Omit a semi-colon in a computer program and the program
fails or gives the wrong result. With HTML, if the mark-up is more or less right,
most browsers will usually accept it. The simplicity has the added benefit that
computers programs to interpret HTML and display web pages are straightforward
to write.
Uniform Resource Locator (URL)
The second key component of the web is the Uniform Resource Locator, known
as a URL. URLs are ugly to look at but are flexible. They provide a simple addressing
mechanism that allows the web to link information on computers all over the
world. A simple URL is contained in the HTML example in Panel 2.6:
http://www.dlib.org/dlib.html
This URL has three parts:
http is the name of a protocol
www.dlib.org is the domain name of a computer
dlib.html is a file on that computer
Thus an informal interpretation of this URL is, "Using the HTTP protocol,
connect to the computer with the Internet address www.dlib.org, and access the
file dlib.html."
HTTP
In computing, a protocol is a set of rules that are used to send messages between
computer systems. A typical protocol includes description of the formats to
be used, the various messages, the sequences in which they should be sent, appropriate
responses, error conditions, and so on. HTTP is the protocol that is used to
send messages between web browsers and web servers.
The basic message type in HTTP is get. For example, clicking on the hyperlink
with the URL:
http://www.dlib.org/dlib.html
specifies an HTTP get command. An informal description of this command is:
- Open a connection between the browser and the web server that has the domain
name "www.dlib.org".
- Copy the file "dlib.html" from the web server to the browser.
- Close the connection.
MIME types
A file of data in a computer is simply a set of bits, but, to be useful the
bits need to be interpreted. Thus, in the previous example, in order to display
the file "dlib.html" correctly, the browser must know that it is in
the HTML format. The interpretation depends upon the data type of the file.
Common data types are "html" for a file of text that is marked-up
in HMTL format, and "jpeg" for a file that represents an image encoded
in the jpeg format.
In the web, and in a wide variety of Internet applications, the data type is
specified by a scheme called MIME. (The official name is Internet Media
Types.) MIME was originally developed to describe information sent by electronic
mail. It uses a two part encoding, a generic part and a specific part. Thus
text/ascii is the MIME type for text encoded in ASCII, image/jpeg is the type
for an image in the jpeg format, and text/html is text marked-up with HMTL tags.
As described in Chapter 12, there is a standard set of MIME types that are used
by numerous computer programs, and additional data types can be described using
experimental tags.
The importance of MIME types in the web is that the data transmitted by an
HTTP get command has a MIME type associated with it. Thus the file "dlib.html"
has the MIME type text/html. When the browser receives a file of this type,
it knows that the appropriate way to handle this file is to render it as HTML
text and display it in the screen.
Many computer systems use file names as a crude method of recording data types.
Thus some Windows programs use file names that end in ".htm" for file
of HMTL data and Unix computers use ".html" for the same purpose.
MIME types are a more flexible and systematic method to record and transmit
typed data.
Information on the web
The description of the web so far has been technical. These simple components
can be used to create many applications, only some of which can be considered
digital libraries. For example, many companies have a web site to describe the
organization, with information about products and services. Purchases, such
as airline tickets, can be made from web servers. Associations provide information
to their members. Private individuals have their own web sites, or personal
home pages. Research results may be reported first on the web. Some web sites
clearly meet the definition of a digital library, as managed collections of
diverse information. Others do not. Many web sites meet the definition of junk.
In aggregate, however, these sites are all important for the development of
digital libraries. They are responsible for technical developments beyond the
simple building blocks described above, for experimentation, for the establishments
of conventions for organizing materials, for the increasingly high quality of
graphical design, and for the large number of skilled creators, users, and webmasters.
The size of the web has stimulated numerous companies to develop products, many
of which are now being used to build digital libraries. Less fortunately, the
success of all these web sites frequently overloads sections of the Internet,
and has generated social and legal concerns about abusive behavior on the Internet.
|
Panel 2.7
The World Wide Web Consortium
No central organization controls the web, but there is
a need for agreement on the basic protocols, formats, and practices, so
that the independent computer systems can interoperate. In 1994, recognizing
this need, the Massachusetts Institute of Technology created the World
Wide Web Consortium (W3C) and hired Tim Berners-Lee, the creator of the
web, as its director. Subsequently, MIT added international partners at
the Institut National de Recherche en Informatique et en Automatique in
France and the Keio University Shonan Fujisawa Campus in Japan. W3C is
funded by member organizations who include most of the larger companies
who develop web browsers, servers, and related products.
W3C is a neutral forum in which organizations work together
on common specifications for the web. It works through a series of conferences,
workshops, and design processes. It provides a collection of information
about the web for developers and users, especially specifications about
the web with sample code that helps to promote standards. In some areas,
W3C works closely with the Internet Engineering Task Force to promulgate
standards for basic web technology, such as HTTP, HTML, and URLs.
By acting as a neutral body in a field that is now dominated
by fiercely competing companies, W3C's power depends upon its ability
to influence. One of its greatest successes was the rapid development
of an industry standard for rating content, known as PICS. This was a
response to political worries in the United States about pornography and
other undesirable content being accessible by minors. More recently it
has been active in the development of the XML mark-up language.
Companies such as Microsoft and Netscape sometimes believe
that they gain by supplying products that have non-standard features,
but these features are a barrier to the homogeneity of the web. W3C deserves
much of the credit for the reasonably coherent way that the web technology
continues to be developed.
|
Conventions
The first web sites were created by individuals, using whatever arrangement
of the information they considered most appropriate. Soon, conventions began
to emerge about how to organize materials. Hyperlinks permit an indefinite variety
of arrangements of information on web sites. Users, however, navigate most effectively
through familiar structures. Therefore these conventions are of great importance
in the design of digital libraries that are build upon the web. The conventions
never went through any standardization body, but their widespread adoption adds
a coherence to the web that is not inherent in the basic technology.
-
Web sites. The term "web site" has already been used several
times. A web site is a collection of information that the user perceives
to be a single unit. Often, a web site corresponds to a single web server,
but a large site may be physically held on several servers, and one server
may be host to many web sites.
The convention rapidly emerged for organizations to give their web site
a domain name that begins "www". Thus "www.ibm.com"
is the IBM web site"; "www.cornell.edu" is Cornell University;
"www.elsevier.nl" is the Dutch publisher, Elsevier.
-
Home page. A home page is the introductory page to a collection
of web information. Almost every web site has a home page. If the address
in a URL does not specify a file name, the server conventionally supplies
a page called "index.html". Thus the URL:
http://www.loc.gov/
is interpreted as http://www.loc.gov/index.html. It is the home page of
the Library of Congress. Every designer has slightly different ideas about
how to arrange a home page but, just as the title page of a book follows
standard conventions, home pages usually provide an overview of the web
site. Typically, this combines an introduction to the site, a list of contents,
and some help in finding information.
The term "home page" is also applied to small sets of information
within a web site. Thus it is common for the information relevant to a specific
department, project, or service to have its own home page. Some individuals
have their own home pages.
-
Buttons. Most web pages have buttons to help in navigation. The
buttons provide hyperlinks to other parts of the web site. These have standard
names, such as "home", "next", and "previous".
Thus, users are able to navigate confidently through unfamiliar sites.
-
Hierarchical organization. As seen by the user, many web sites are
organized as hierarchies. From the home page, links lead to a few major
sections. These lead to more specific information and so on. A common design
is to provide buttons on each page that allow the user to go back to the
next higher level of the hierarchy or to move horizontal to the next page
at the same level. Users find a simple hierarchy an easy structure to navigate
through without losing a sense of direction.
The web as a digital library
Some people talk about the web technology as though it were an inferior stop-gap
until proper digital libraries are created. One reason for this attitude is
that members of other professions having difficulty in accepting that definitive
work in digital libraries was carried out by physicists at a laboratory in Switzerland,
rather than by well-known librarians or computer scientists. But the web is
not a detour to follow until the real digital libraries come along. It is a
giant step to build on.
People who are unfamiliar with the online collections also make derogatory
statements about the information on the web. The two most common complaints
are that the information is of poor quality and that it is impossible to find
it. Both complaints have some validity, but are far from the full truth. There
is an enormous amount of material on the web; much of the content is indeed
of little value, but many of the web servers are maintained conscientiously,
with information of the highest quality. Finding information on the web can
be difficult, but tools and services exist that enable a user, with a little
ingenuity, to discover most of the information that is out there.
Today's web, however, is a beginning, not the end. The simplifying assumptions
behind the technology are brilliant, but these same simplifications are also
limitations. The web of today provides a base to build the digital libraries
of tomorrow. This requires better collections, better services, and better underlying
technology. Much of the current research in digital libraries can be seen as
extending the basic building blocks of the web. We can expect that, twenty five
years from now, digital libraries will be very different; it will be hard to
recall the early days of the web. The names "Internet" and "web"
may be history or may be applied to systems that are unrecognizable as descendants
of the originals. Digital libraries will absorb materials and technology from
many places. For the next few years, however, we can expect to see the Internet
and the web as the basis on which the libraries of the future are being built.
Just as the crude software on early personal computers has developed into modern
operating systems, the web can become the foundation for many generations of
digital libraries.
Last revision of content: January 1999
Formatted for the Web: December 2002
(c) Copyright The MIT Press 2000