改善你的 HTTP web 服务客户的第一步就是用 User-Agent 适当地鉴别你自己。为了做到这一点, 你需要远离基本的 urllib 而深入到 urllib2。
例 11.4. urllib2 介绍
>>> import httplib
>>> httplib.HTTPConnection.debuglevel = 1  >>> import urllib2
>>> request = urllib2.Request('http://diveintomark.org/xml/atom.xml')
>>> import urllib2
>>> request = urllib2.Request('http://diveintomark.org/xml/atom.xml') 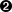 >>> opener = urllib2.build_opener()
>>> opener = urllib2.build_opener()  >>> feeddata = opener.open(request).read()
>>> feeddata = opener.open(request).read()  connect: (diveintomark.org, 80)
send: '
GET /xml/atom.xml HTTP/1.0
Host: diveintomark.org
User-agent: Python-urllib/2.1
'
reply: 'HTTP/1.1 200 OK\r\n'
header: Date: Wed, 14 Apr 2004 23:23:12 GMT
header: Server: Apache/2.0.49 (Debian GNU/Linux)
header: Content-Type: application/atom+xml
header: Last-Modified: Wed, 14 Apr 2004 22:14:38 GMT
header: ETag: "e8284-68e0-4de30f80"
header: Accept-Ranges: bytes
header: Content-Length: 26848
header: Connection: close
connect: (diveintomark.org, 80)
send: '
GET /xml/atom.xml HTTP/1.0
Host: diveintomark.org
User-agent: Python-urllib/2.1
'
reply: 'HTTP/1.1 200 OK\r\n'
header: Date: Wed, 14 Apr 2004 23:23:12 GMT
header: Server: Apache/2.0.49 (Debian GNU/Linux)
header: Content-Type: application/atom+xml
header: Last-Modified: Wed, 14 Apr 2004 22:14:38 GMT
header: ETag: "e8284-68e0-4de30f80"
header: Accept-Ranges: bytes
header: Content-Length: 26848
header: Connection: close
|
|
如果你的 Python IDE 仍旧为上一节的例子而打开着, 你可以略过这一步, 在开启 HTTP 调试 中你能看到网络线路上的实际传输过程。 |
|
|
使用 urllib2 获取 HTTP 资源包括三个处理步骤, 这会有助于你理解这一过程。
第一步是创建 Request 对象, 它接受一个你最终想要获取资源的 URL。 注意这一步实际上还不能获取任何东西。 |
|
|
第二步是创建一个 URL 开启器 (opener)。 这可以使用任何数量的操作者来控制响应的处理。 但你也可以创建一个没有任何自定义处理的开启器, 这就是这里的操作方式。 你将在本章后面探究重定向的部分看到如何定义和使用自定义操作者的内容。 |
|
|
最后一个步骤是, 使用你创建的 Request 对象告诉开启器打开 URL。 因为你能从获得的信息中看到所有调试信息, 这个步骤实际上获得了资源并且把返回数据存储在了 feeddata 中。 |
例 11.5. 用 Request 添加头信息
>>> request
<urllib2.Request instance at 0x00250AA8>
>>> request.get_full_url()
http://diveintomark.org/xml/atom.xml
>>> request.add_header('User-Agent',
... 'OpenAnything/1.0 +http://diveintopython.org/')
>>> feeddata = opener.open(request).read()
connect: (diveintomark.org, 80)
send: '
GET /xml/atom.xml HTTP/1.0
Host: diveintomark.org
User-agent: OpenAnything/1.0 +http://diveintopython.org/
'
reply: 'HTTP/1.1 200 OK\r\n'
header: Date: Wed, 14 Apr 2004 23:45:17 GMT
header: Server: Apache/2.0.49 (Debian GNU/Linux)
header: Content-Type: application/atom+xml
header: Last-Modified: Wed, 14 Apr 2004 22:14:38 GMT
header: ETag: "e8284-68e0-4de30f80"
header: Accept-Ranges: bytes
header: Content-Length: 26848
header: Connection: close
|
|
继续前面的例子; 你已经用你要访问的 URL 创建了 Request 。 |
|
|
使用Request 对象的 add_header 方法, 你能向请求中添加任意的 HTTP 头信息。 第一个参数是头信息, 第二个参数是头信息的值。 User-Agent 的协商指令应该使用如下的特殊格式: 应用名, 跟一个斜线, 跟版本号。 剩下的是自由的格式, 你将看到许多疯狂的变化, 但通常这里应该包含你的应用的 URL。 The User-Agent 通常要记录经过服务器的连同你的请求的其他详细信息, 包含你的应用的 URL , 如果发生错误, 允许服务器管理员通过查看他们的访问日志与你联系。 |
|
|
之前你创建的opener 对象也可以再生, 且它将再次获得相同的 feed, 但是使用了你自定义的 User-Agent 头信息。 |
|
|
这就是你发送的自定义的 User-Agent, 代替了 Python 默认发送的一般的 User-Agent。 若你继续看,会注意到你定义的 User-Agent 头信息, 你实际上发送了一个 User-agent 头信息。 看看有何不同? urllib2 改变了大小写所以只有首字母是大写的。 这没问题,因为 HTTP 规定 头子段名完全是大小写无关的。 |