As noted earlier, the notion of speeding up programs by doing work in parallel (which is the basis of all beowulfery) is hardly new. It dates back to the earliest days of computing, when all computers were so damn slow4.1that people with big pieces of work to do really wanted to speed things up. IBM (which made just about all computers at the time and for a considerable time afterward) wanted to speed things up by doing things in parallel (to sell more computers), but rapidly found that there were some fairly stringent restrictions on how much of a speedup one could get for a given parallelized task. These observations were wrapped up in Amdahl's Law, where Gene Amdahl was an IBM-er who was working on the problem.
To grok4.2Amdahl's law, we must begin by defining the ``speed'' of a program. In
physics, the average speed is the distance travelled divided by the time
it took to travel it. In computers, one does ``work'' instead of
travelling distance, so the speed of the program is sensibly defined to
be the work4.3 done divided by the time it took to do it:
| (4.1) |
Now we must consider ``serial work'' and ``parallel work''. To properly understand all the picky little engineering details of a beowulf we must begin by thoroughly understanding how to ``parallelize'' a task. Obviously I don't want to talk about parallelizing a computer program as my example. If you already know how to parallelize computer programs, why are you reading this book (except maybe for a good laugh)?
For better or worse, the example task I've chosen to demonstrate parallel and serial work is one that I hope all of my readers have undertaken at some point in their lives. It is utterly prosaic, yet it holds important lessons for us. A very Zen thing.
Let us (therefore) imagine that we are building a model airplane. Just in case some of you have never built model airplanes, allow me to describe the standard procedure. First you open the box. Inside is a set of instructions4.4 that are usually numbered 1, 2, 3 and so on. There are three or four plastic ``trees'' with little-bitty molded plastic parts from which one assembles wheels, wings, propellers or jets, the cockpit, and sometimes a stand4.5. There is usually a sheet of decals as well, that one usually puts on at the end to put strange things like the numbers U94A on the tail and a shark's mouth on the front. One needs to provide a workspace containing a brain (yours)4.6 and things like fingers, a sharp instrument for cutting the plastic free from the trees, glue, and possibly paint4.7.
Serial computational work is like building the airplane from the pieces, following the instructions one at a time, in order. First we assemble the body. Then we assemble the cockpit. Then we build and attach the left wing. Then we build and attach the right wing. Then we build the tail section. And so on. Sometimes you can do things a bit out of order (build the right wing and then the left wing, for example). Other times building things out of order will leave you pulling the airplane apart to insert the wheel assemblies into the body sockets before gluing the body halves together. Occasionally one has to put parts aside and wait for ill-defined periods (like for the glue to dry for some sub-assembly) before proceeding. All of these have analogs in computation. In fact, I'm going to beat this metaphor half to death in the following pages, so I hope you liked building model airplanes way back when.
Suppose now that you are building the airplane with a friend. Only one of you can build the body, as there is only one body. Only one of you can build the cockpit. But there are two wings...
Aha! We've discovered parallel work. You hand the instructions and parts for one wing to your friend and you both build one wing each at the same time. Then you attach them one at a time. If you do nothing else in parallel, you complete your airplane in a time shorter than what it would have taken you working alone by (approximately) one wing! Wowser!
Is this the fastest you could have built it with your friend's help? Probably not. There are also several wheel assemblies that could be built at the same time. Also, perhaps you could have worked out of order, with him building the tail or the display rack while you built the cockpit. He might have had to wait a bit for you if he finished earlier, and while he was waiting he might have been able to attach propellers to the engines or attach decals. Or, one might have to put the wings on after the cockpit and before the decals for some reason, so he may have just had to wait until the cockpit was done to do something useful.
If one pauses for a moment to think about it, we automatically parallelize all sorts of tasks in our daily lives as a matter of simple survival4.8. One way or another, a given organization of any task has some time spent performing subtasks that can be done only serially (one subtask after another in just one workspace) and some time spent performing subtasks that could be done in parallel (using more than one workspace to independently work on different sets of sequential subtasks). There are obviously lots of ways to split tasks up, and what works best depends on many things.
Running a program on a computer is also executing a series of
small tasks specified by instructions (code) that cause an agent (the
CPU) to act on parts (data) in some environment (the computer) equipped
with a set of tools (the peripherals) just like building a model
airplane. If we identify the serial and parallelizable parts, we can
then rewrite our equation for the rate at which a single computer
processor can complete a particular piece of work ![]() as:
as:
| (4.2) |
Now, even with ``perfect'' parallelization and many (![]() ) processors,
the program cannot take less than
) processors,
the program cannot take less than ![]() to complete. Even if the entire
population of the world were in your kitchen while you were working on
the model airplane, you have to complete the body yourself, one step at
a time. The best you can do is let all those folks work on the wings
and the tail and so forth while you work on the body so as much is done
in parallel as possible when the time comes to take the next serial step
in assembly. Obviously, the absolute most that having friends help can
do for you is reduce the time required to complete the parallel work to
zero (in fact, you can never quite reach zero). The maximum rate of
work one could EVER expect to see with the help of your friends is thus:
to complete. Even if the entire
population of the world were in your kitchen while you were working on
the model airplane, you have to complete the body yourself, one step at
a time. The best you can do is let all those folks work on the wings
and the tail and so forth while you work on the body so as much is done
in parallel as possible when the time comes to take the next serial step
in assembly. Obviously, the absolute most that having friends help can
do for you is reduce the time required to complete the parallel work to
zero (in fact, you can never quite reach zero). The maximum rate of
work one could EVER expect to see with the help of your friends is thus:
| (4.3) |
Believe it or not, when we add a single variable (the number of friends you have to split up the parallelizable work with), this simple observation is:
Amdahl's Law (Gene Amdahl, 1967)
Ifwhere the result is expressed in fractions of the time spent in the distinct serial or parallelizable parts of a calculation:is the fraction of a calculation that is serial and
the fraction that can be parallelized, then the greatest speedup that can be achieved using P processors is:
which has a limiting value of
for an infinite number of processors.
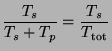 |
(4.4) | ||
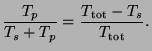 |
(4.5) |
Since we're going to derive complicated variants of this law (that
are much better approximators to the speedup bounds) we'd better see how
this is derived. We note that the best we can do with parallel work is
split it up into ![]() pieces that are all done at the same time so that
the ideal time required to complete it turns into
pieces that are all done at the same time so that
the ideal time required to complete it turns into ![]() . The rate of
completion of our task with
. The rate of
completion of our task with ![]() processors then becomes:
processors then becomes:
| (4.6) |
| (4.7) |
Note again that this is the best one can hope to achieve unless
the very act of parallelization changes the algorithm used to do the
parallel work and/or the hardware interaction into something that
reduces ![]() (which can happen)4.9. No matter how many processors are employed, if a
calculation has a 10% serial component (or
(which can happen)4.9. No matter how many processors are employed, if a
calculation has a 10% serial component (or ![]() ), the maximum
speedup obtainable is 10. If you spend half the time building an
airplane doing things that only one person can do, the best speedup you
can hope for is for all the other tasks to be done in zero additional
time by an infinite number of friends, for a speedup of two.
), the maximum
speedup obtainable is 10. If you spend half the time building an
airplane doing things that only one person can do, the best speedup you
can hope for is for all the other tasks to be done in zero additional
time by an infinite number of friends, for a speedup of two.