Chapter 10. RDF, RDF Tools, and the Content Model
Chapter 9 introduced the Resource Description Framework (RDF) as the basis for building display data in the interface, where XUL templates take RDF-based data and transform it into regular widgets. But RDF is used in many other more subtle ways in Mozilla. In fact, it is the technology Mozilla uses for much of its own internal data handling and manipulation.
RDF is, as its name suggests, a framework for integrating many types of data that go into the browser, including bookmarks, mail messages, user profiles, IRC channels, new Mozilla applications, and your collection of sidebar tabs. All these items are sets of data that RDF represents and incorporates into the browser consistently. RDF is used prolifically in Mozilla, which is why this chapter is so dense.
This chapter introduces RDF, provides some detail about how Mozilla uses RDF for its own purposes, and describes the RDF tools that are available on the Mozilla platform. The chapter includes information on special JavaScript libraries that make RDF processing much easier, and on the use of RDF in manifests to represent JAR file contents and cross-platform installation archives to Mozilla.
Once you understand the concepts in this chapter, you can make better use of data and metadata in your own application development.
10.1. RDF Basics
RDF has two parts: the RDF Data Model and the RDF Syntax (or Grammar). The RDF Data Model is a graph with nodes and arcs, much like other data graphs. More specifically, it's a labeled-directed graph. All nodes and arcs have some type of label (i.e., an identifier) on them, and arcs point only in one direction.
The RDF Syntax determines how the RDF Data Model is represented, typically as a special kind of XML. Most XML specifications define data in a tree-like model, such as XUL and XBL. But the RDF Data Model cannot be represented in a true tree-like structure, so the RDF/XML syntax includes properties that allow you to represent the same data in more than one way: elements can appear in different orders but mean the same thing, the same data can be represented as a child element or as a parent attribute, and data have indirect meanings. The meaning is not inherent in the structure of the RDF/XML itself; only the relationships are inherent. Thus, an RDF processor must make sense of the represented RDF data. Fortunately, an excellent RDF processor is integrated into Mozilla.
10.1.1. RDF Data Model
Three different types of RDF objects are the basis for all other RDF concepts: resources, properties, and statements. Resources are any type of data described by RDF. Just as an English sentence is comprised of subjects and objects, the resources described in RDF are typically subjects and objects of RDF statements. Consider this example:
Eric wrote a book.
Eric is the subject of this statement, and would probably be an RDF resource in an RDF statement. A book, the object, might also be a resource because it represents something about which we might want to say more in RDF -- for example, the book is a computer book or the book sells for twenty dollars. A property is a characteristic of a resource and might have a relationship to other resources. In the example, the book was written by Eric. In the context of RDF, wrote is a property of the Eric resource. An RDF statement is a resource, a property, and another resource grouped together. Our example, made into an RDF statement, might look like this:
(Eric) wrote (a book)
Joining RDF statements makes an entire RDF graph.
 | We are describing the RDF data model here, not the RDF syntax. The RDF syntax uses XML to describe RDF statements and the relationship of resources. |
As mentioned in the introduction, the RDF content model is a labeled-directed graph, which means that all relationships expressed in the graph are unidirectional, as displayed in Figure 10-1.
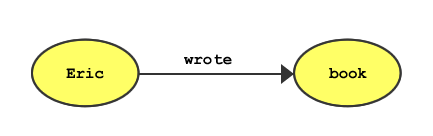
A resource can contain either a URI or a literal. The root resource might have a URI, for example, from which all other resources in the graph descend. The RDF processor continues from the root resource along its properties to other resources in the graph until it runs out of properties to traverse. RDF processing terminates at a literal, which is just what it sounds like: something that stands only for itself, generally represented by a string (e.g., "book," if there were no more information about the book in the graph). A literal resource contains only non-RDF data. A literal is a terminal point in the RDF graph.
For a resource to be labeled, it must be addressed through a universal resource identifier (URI). This address must be a unique string that designates what the resource is. In practice, most resources don't have identifiers because they are not nodes on the RDF graph that are meant to be accessed through a URI. Figure 10-2 is a modified version of Figure 10-1 that shows Eric as a resource identifier and book as a literal.

Resources can have any number of properties, which themselves differ. In Figure 10-2, wrote is a property of Eric. However, resources can also have multiple properties, as shown in Figure 10-3.
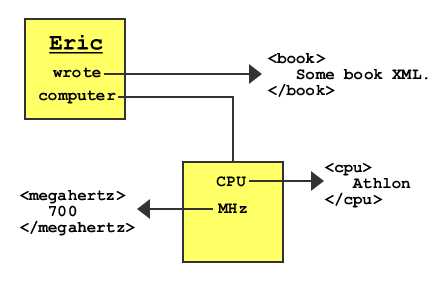
The RDF graph in Figure 10-3 has five nodes, two resources, and three literals. If this graph were represented in XML, it would probably have three different XML namespaces inside of it: RDF/XML, a book XML specification, and a computer XML specification. In English, the graph in Figure 10-3 might be expressed as follows:
Eric wrote a book of unknown information. Eric's computer is 700 MHz and has an Athlon CPU.
Note that if Eric wrote a poem and a book, it would be possible to have two wrote properties for the same resource. Using the same property to point to separate resources is confusing, however. Instead, RDF containers (see the section Section 10.1.2.2, later in this chapter) are the best way to organize data that would otherwise need a single property to branch in this way.
10.1.1.1. RDF URIs relating to namespaces
The URIs used in RDF can be part of the element namespace. (See Section 2.2.3 and in Section 7.1.3 for more information about XML namespaces.) This use is especially true for properties. Some namespaces can be created from previous examples:
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:book="http://www.oreilly.com/rdf#" xmlns:comp="my.computer.hardware#"
When you use namespaces, the graph looks much different, as shown in Figure 10-4.

10.1.1.2. RDF triples: subject, predicate, and object
A triple is a type of RDF statement. While an RDF statement can be a loose collection of resources, properties, and literals, a triple typically defines a tighter relationship between such elements.
The first part of a triple is the subject. This part is the resource described by the triple. The second part of the triple is the predicate. This part is a subject's property, a thing that joins it with something else. The third part is the object, which is either a resource or a literal.
RDF triples are significant because their stricter semantics guarantee the relationship between parts. A triple is a more formal version of the RDF statement, which is used more broadly. In Figure 10-4, all statements are formally subject > predicate > object, so those statements are triples.
10.1.1.3. RDF data model terminology
When reading RDF specifications, documentation, examples, and other related material on the Internet, you can encounter a dizzying array of terms that mean the same thing. Table 10-1 should help clarify these different terms. The italicized versions of the synonyms all do not technically mean the same thing, but are loose synonyms whose meanings depend on the context in which they are used.
Table 10-1. Synonyms in RDF
|
Common term |
Synonyms |
|---|---|
|
Resource |
Subject, object |
|
Resource identifier |
Name, (resource) URI, ID, identifier, URL, label |
|
Properties |
Attributes |
|
Statement |
Triple, tuple, binding, assertion |
|
Subject |
Source, resource, node, root |
|
Predicate |
Arc, (statement) URI, property, atom |
|
Object |
Value, resource, node, literal |
10.1.2. RDF Syntax
Mozilla uses XML to represent RDF data. In 1999, the W3C defined the RDF/XML specification syntax to make it the most common way RDF is used. The RDF/XML format is sometimes called the RDF serialization syntax because it allows RDF models to be sent easily from one computer application to another in a common XML format.
When an application reads an RDF file, the Mozilla RDF processor builds a graphical interpretation in-memory. In this section, you learn how to build an RDF file from scratch and see what the graph looks like after running through Mozilla's RDF processor.
| RDF:RDF is a common namespace representation of RDF/XML data and is the one most frequently used in Mozilla files. However, it can be hard to read, so this chapter uses rdf:RDF. The W3C also used rdf:RDF in the RDF recommendation document. |
10.1.2.1. Examining a simple RDF file
We begin with an example of an RDF file whose basic layout and simple syntax can be a model for the more advanced data introduced later. The RDF file shown in Example 10-1 is a list of three types of "flies," with the context of those "flies" inside a "jar." Example 10-1 also contains a namespace that defines these types of flies and shows the rdf and fly XML intertwined.
<rdf:Description> is the tag used to outline a resource. Example 10-1 shows how the about attribute references the resource identifier and makes this resource unique in the document. Two resources cannot have the same about value in a document, just as tags cannot share an id in an XML document. Both attributes guarantee the unique nature of each element and relationship.
<rdf:Description about="http://my.jar-of-flies.com">
<fly:types>
<rdf:Bag>http://my.jar-of-flies.com, is the subject shown in the previous code snippet. My jar of flies is a resource definition and defines only what flies are inside of the statement. The predicate, which addresses a property in the resource, is defined by the tag <types> (of the http://xfly.mozdev.org/fly-rdf# namespace).
The final part of the statement, the object, is the actual data of the predicate and a container of type bag. The container is an RDF resource that "holds," or points to, a collection of other resources. In the next section, container types are discussed in depth. Figure 10-5 illustrates how the triple originates from the root subject and includes the container object.
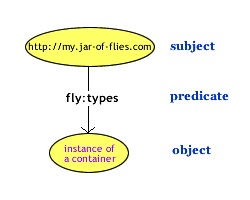
In this case, an RDF statement is extracted from the example, but no useful data is reached. Little can be done with an empty RDF container, and two more steps are needed to reach literals that contain names of the flies.
10.1.2.2. RDF containers
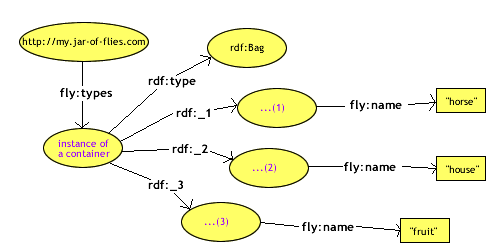
Containers are a list of resources or literals. They are a form of RDF resource. There are three different container types: bag, sequence, and alternative. Bag is an unordered list of items, whereas sequence is an ordered list of items. They both allow duplicate values. Alternative is a list of values that could replace a particular property in a resource. Sequence is the most popular container for use in Mozilla applications because it frequently uses ordered lists of data. A container's graphical definition is an entire separate statement about its type and the items it contains. In Figure 10-6, you can see the type of the container defined in the RDF statement with the property rdf:type. The remaining properties are the container's items.

Once the container is defined, you can examine its collection of elements. At this point in the RDF code, direct comparisons can again be made from the code to the graph:
<rdf:Bag>
<rdf:li>
<rdf:Description ...Here, the <rdf:li> tag is similar to the <li> tag in HTML, which stands for "list item." Moving from code to graph, the new representation is shown in Figure 10-6.
In Figure 10-6, the subject is the instance of the container. This statement does not begin from rdf:Bag because that resource is only a type definition. The actual items in the container originate from the instance created in memory by any RDF processor, including Mozilla's.
| Mozilla's RDF processor fills in the rdf:*(1) of the resource identifier in Figure 10-6 with a hashed value. The same is true for the container's resource identifier. The actual values come out as something like rdf:#$0mhkm1, though the values change each time the RDF document is loaded. |
Objects inside of the container have properties identified automatically as rdf:_1, rdf:_2, etc., as defined by the RDF model specification. However, RDF applications such as Mozilla may use different identifiers to differentiate list objects.
10.1.2.3. Literals
The final statement in Example 10-1 allows the predicate to reach the text data, the literal "horse" shown in Figure 10-7. Note that the about reference on the Description is fictitious RDF, but it demonstrates the difference between a resource and a literal.
<rdf:Description about="rdf:*(1)" fly:name="Horse"/>

The previous RDF code for the literal is syntactic shorthand. Using this type of shortcut can make RDF much easier to read. The previous code snippet is the same as the longer and more cumbersome one shown here:
<rdf:Description about="rdf:*(1)">
<fly:name>Horse</fly:name>
</rdf:Description>The shorthand version of this statement can be useful when you have a lot of data or when you want to use one syntax to show all relationships in the graph.
10.1.2.4. The RDF syntax and RDF graphs
Figure 10-8 shows the entire RDF graph for the RDF file in Example 10-1. This graph was compiled by combining the concepts you've seen in Figures 10-5 through 10-7.
As you can see, the statements fit together quite nicely. Four resources originate from the container, and one is the container type definition. The other two properties are numbered according to their order in the RDF file.
10.1.3. Building an RDF File from Scratch
Now that you understand the basic principles of a simple RDF file, this section steps through the creation of an RDF file from information found in regular text:
There is a jar with the name urn:root. Inside of it there are two types of flies listed as House and Horse.
There are three Horse flies. The Face Fly, coded in green, is officially identified as "musca autumnalis". The Stable Fly, coded in black, has the identification "stomoxys_calcitrans." The red-coded Horn Fly, located in Kansas, is identified as "haematobia_irritans."
There are also three house flies. "musca_domestica," coded in brown, has the name "Common House Fly." A gray fly named "Carrion Fly" has the ID "sarcophagid" and is found globally. Finally, The "Office Fly," coded with white, is prevalent in the Bay Area.
You can use the techniques described here to model the data you want in your application: spreadsheet-like rosters of people, family trees, or catalogs of books or other items.
10.1.3.1. Identify namespaces
The new RDF file will have three namespaces including the RDF namespace. The result is two different data types that are connected in an RDF graph. For the sake of the example, one namespace is not in the standard URL format. Here is how the RDF file namespaces are set up:
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:fly="http://xfly.mozdev.org/fly-rdf#"
xmlns:location="fly-location#">
</rdf:RDF>10.1.3.2. Root resource
This file's root resource is an urn:root, which is the conventional name for root nodes in Mozilla's RDF files. When rendering RDF files, defining a root node for processing the document can be useful -- especially when building templates. This root node can be entered as the first item in the file:
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:fly="http://xfly.mozdev.org/fly-rdf#"
xmlns:location="fly-location#">
<rdf:Description about="urn:root">
</rdf:Description>
</rdf:RDF>10.1.3.3. Root sequence
Next, a generic tag needs to be used to specify a sequence of "fly" data. As in Example 10-2, <fly:list> is used as a list of fly types. This tag is a generic name because of the way XUL templates process lists of RDF data. If a list of data has sublists, as in the following examples, then they must use the same tag name to recurse correctly for the data they contain.
Example 10-2 represents all the information given in the first paragraph of the text example: "There is a jar set up with the name urn:root. Inside of it there are two types of flies, listed as House and Horse."
An RDF sequence resides with its list of resources inside <fly:list>. Here, shorthand RDF specifies a label with the fly:label attribute. The ID attribute within this sequence is actually a pointer to the main definition of the resource described by an about attribute of the same value. The about attribute includes a # in its identifier, much like HTML anchors use <a href="#frag"> to refer to <a name="frag">. For example, ID="Horse" points to about="#Horse" elsewhere in the file, allowing you to add to the description of any element with new properties and resources.
10.1.3.4. Secondary sequences and literals
The Horse and House resources need to be defined next. Example 10-3 shows the creation of Horse from the second paragraph. The process for creating House is almost identical.
Here the shorthand RDF definition continues to use only the attributes. Again, a <fly:list> is defined and the items inside it are listed. The listed values have multiple attribute values, all of which are RDF literals. In longhand with RDF showing all literals, the last item would be written out as follows:
<rdf:li>
<rdf:Description about="haematobia_irritans ">
<fly:label>Horn Fly</fly:label>
<fly:color>red</fly:color>
<location:location>Kansas</location:location>
</rdf:Description>
</rdf:li>The two different namespace literals are both resource attributes. haematobia_irritans is used as the resource identifier because it is a unique value among all data.
Laying out the data in the same pattern gives you the final, full RDF file in Example 10-4.
Example 10-4 shows the RDF data used in several template examples in Chapter 9. Example 9-4 includes the 10-4.rdf datasource, as do many of those templates. You can copy the data out of Example 10-4 and into a file of the same name to use as a datasource.