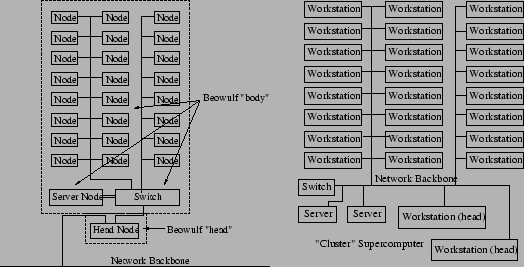
Examine the schema in figure 1.1. On the left, we have the ``true beowulf''. The accepted definition of a true beowulf is that it is a cluster of computers (``compute nodes'') interconnected with a network with the following characteristics:
These are the necessary requirements. Note well that they both specify certain key features of the layout and architecture and contain an application specification. A cluster ``like'' a beowulf cluster that fails in any of these requirements may be many things, but a beowulf is not one of them. In addition there are a few other things that characterize most beowulfs and that at least some would argue belong in the ``necessary'' list above.
These requirements are a bit ``softer'' - a purist (and the list does have its purists) might insist on one or more of them but at some point a list of criteria like this obstructs creativity and development as much as it provides a ``proven'' structure. As you can probably tell, I'm not a purist, although I appreciate the virtues of the primary definition and hope to communicate a full understanding of those virtues in the following chapters. Let's examine these secondary requirements and make editorial comments.
Many folks on the beowulf list (including myself) are perfectly happy to recognize a cluster with all the architectural characteristics but running FreeBSD (an open source, unix-like operating system) as a ``beowulf'', while they would (and periodically do, rather ``enthusiastically'') reject the same cluster running closed-source Windows NT.
The point of beowulfery has never been to glorify Linux per se (however much or little it might deserve glorification) but rather to explore the possibilities of building supercomputers out of the mass-market electronic equivalent of coat hangers and chewing gum. An essential part of this is an open source operating system and development environment, as one's problems and optimizations will often require modification of e.g. the kernel, the network device drivers, or other task-specific optimizations that require the sources. Let's understand this.
Debugging certain problems has historically required access to the kernel sources and has been none too easy even with them in hand. If a network parallel computation fails, is it because of your parallel code or because the network driver or TCP stack is broken? If you use a closed-source, proprietary operating system and try to seek vendor support for a problem like this, the uniform answer they'll give you will be "your parallel program" even though your code works fine on somebody else's operating system and many problems encountered in beowulfery have indeed turned out to be in the kernel. Sometimes those problems are features of the kernel or its components.
Deliberate features of the TCP stack, for example, are intended to produce robustness across a wide area network but can cause nasty failures of your TCP-based parallel codes1.5. If you encounter one of these problems, you personally may not be able to fix it, but because Linux is open source, it is fairly likely that one of the real kernel-hacking deities of the beowulf or kernel list will be able to help you. Sometimes ``hacks'' of the kernel that ``break'' it (or mistune it) for general purpose usage can be just the ticket to improve efficiency or resolve some beowulf-specific bottleneck.
Indeed, several important beowulf tools have required a custom kernel to operate, and the only reason that these tools exist at all is because a group of ``visionaries'' who also happened to be damn good programmers had access to the kernel sources and could graft in the modifications essential to their tool or service. MOSIX is one example. bproc and the Scyld beowulf package are another1.6.
Access to the (open, non-proprietary kernel and other) source is thus essential to beowulfery, but it doesn't (in my opinion) have to be Linux/GNU source. A warning for newbies, though - if you want to be able to get ``maximum help'' from the list, it's a good idea to stick with Linux because it is what most of the list members use and you'll get the most and best help that way. For example, Don Becker, one of the primary inventors of the beowulf, goes to Linux meetings and conferences and Expos, not (as far as I know) FreeBSD conferences and Expos. So do most of the other ``experts'' on the beowulf list. There are persons on the list running FreeBSD-based beowulfs (as well as a number of general Unix gurus who don't much care what flavor of *nix you run - they can manage it), but not too many.
The second requirement originates from the notion that a beowulf is architecturally a ``single parallel supercomputer'' dedicated only to supercomputing and hence has a single point of presence on an outside network, generally named something interesting and evocative1.7. However, there are sometimes virtues in having more than one head node and are often virtues in having a separate disk server node or even a whole farm of ``disk nodes''1.8. Beowulf design is best driven (and extended) by one's needs of the moment and vision of the future and not by a mindless attempt to slavishly follow the original technical definition anyway.
The third requirement is also associated with the idea that the supercomputer is a single entity and hence ought to live in just one place, but has a more practical basis. One reason for the isolation and dedication is to enable ``fine grained synchronous'' parallel calculations (code with ``barriers'' - which will be defined and discussed later) where one needs to be able to predict fairly accurately how long a node will take to complete a given parallel step of the calculation. This is much easier if all the nodes are identical. Otherwise one has to construct some sort of table of their differential speeds (in memory-size dependent context, which can vary considerably, see the chapter on hardware profiling and microbenchmarking) and write your program to distribute itself in such a way that all nodes still complete steps approximately synchronously.
However, it is easy to start with all nodes identical if one is ``rich'' and/or buys them all at once, but difficult to keep them that way as nodes (or parts of nodes) break and are replaced, or as Moore's Law inexorably advances system performance and you want or need to buy new nodes to upgrade your beowulf1.9. Again, it isn't worth quibbling about whether mixing 800 MHz nodes with 400 MHz nodes (while otherwise preserving the beowulf architecture) makes the resulting system ``not a beowulf''. This is especially true if one's task partitions in some way that permits both newer and older nodes to be efficiently used. The PVFS project1.10 is just one kind of task partitioning that would do so - run the PVFS on the older nodes (where speed and balance are likely determined by the disk and network and not memory or CPU anyway) and run the calculation on the newer nodes.
One of the major philosophical motivations for beowulfery has always been to save money - to get more computing (and get more of Your Favorite Work done) for less money. That's why you bought this book1.11, remember? If you didn't care about money you would have called up one of the many Big Iron companies who would have been more than happy to relieve you of a million or four dollars for what a few hundred thousand might buy you in a beowulfish architecture and never had to learn or do a damn thing1.12. Mixed node architectures extends the useful lifetime of the nodes you buy and can ultimately save you money.
Similar considerations attend the use of a single beowulf to run more than one different computation at a time, which is an obvious win in the event that calculation A saturates its parallel speedup when it is using only half the nodes. If one can (and it would seem silly not to) then one could always run calculation A on some of the 800 MHz nodes and calculation B (which might be less fine grained or could even be embarrassingly parallel) on the rest and all the older 400 MHz nodes without the cluster suddenly hopping out of the ``true beowulf'' category.
So now you know what a beowulf is. What about something that looks a lot like a beowulf (matches on ``most'' of the necessary criteria, but misses on just one or two counts)? It's not a beowulf, but it might still behave like one and be similarly useful and cost effective. Sometimes so cost effective that it is literally free - a secondary use of hardware you already have lying around or in use for other purposes.
This brings us to the second question (and second figure). The ``cluster supercomputer'' schematized there looks a lot like a beowulf. There are a bunch of commodity workstations that can function as ``nodes'' in a parallel calculation. There is a commodity network whereby they can be controlled and communicate with one another as the calculation proceeds. There are server(s). There are ``head nodes'' (which are themselves just workstations). We can certainly imagine that this cluster is running Linux and is being used to perform HPC calculations among other things.
Such a ``cluster'' is called variously a ``Network of Workstations'' (NOW), a ``Cluster of Workstations'' (COW), a ``Pile of PC's'' (POP) or an ``Ordinary Linked Departmental'' (OLD) network1.13.
A cluster like this isn't, technically a beowulf. It isn't isolated. The ``nodes'' are often doing several things at once, like letting Joe down the hall read his mail on one node while Jan upstairs is browsing the web on hers. So is the network; it is delivering Joe's mail and carrying HTML traffic to and from Jan's system. These tiny, unpredictable loads make such an architecture less than ideal for fine grained, synchronous calculations where things have to all finish computational steps at the same time or some nodes will have to wait on others.
However, those little loads on average consume very little of the computational and networking capacity of the average modern network. There is plenty left over for HPC calculations. Best of all, in many cases this computational resource is free in that Joe and Jan have to have computers on their desk anyway in order to do their work (however little of the total capacity of that computer they on average consume). Most users hardly warm up their CPUs doing routine tasks like text processing and network browsing. They are more likely to consume significant compute resources when they crank up graphical games or encode MP3s!
For obvious reasons many of the things one needs to know to effectively perform parallel HPC calculations on a true beowulf apply equally well to any OLD network1.14. For that reason, this book is also likely to be of use to and provide specific chapters supporting distributed parallel computing in a heterogeneous environment like an OLD network - including those made out of old systems. Even though they don't technically make up a beowulf.
For the rest of the book, I'm going to use the term ``beowulf'' and ``cluster'' interchangeably - except when I don't. I'll try to let you know when it matters. If I want to emphasize something that really only applies to a beowulf I'll likely use a phrase like ``true beowulf'' and support this in context. Similarly, it should be very clear that when I talk about a compute cluster made up of workstations spread out over a building with half of them in use by other people at any given time, I'm talking about a NOW or COW but not a ``true beowulf''.
The beowulf list respects this association - a good fraction of the participants are interested in HPC cluster computing in general and could care less if the cluster in question is technically a beowulf. Others care a great deal but are kind enough to tolerate an eclectic discussion as long as it doesn't get too irrelevant to true beowulfery. Many (perhaps most) of the issues to be confronted are the same, after all, and overall the beowulf list has a remarkably high signal to noise ratio.
Given that we're going to talk about a fairly broad spectrum of arrangements of hardware consonant with the beowulfish ``recipe'' above, it makes sense to establish, early on, just what kinds of work (HPC or not) that can sensibly be done, in parallel, on any kind of cluster. Suppose you have a bunch of old systems in a closet, or a bunch of money you want to turn into new systems to solve some particular problem, or want to recover cycles in a departmental network: Will the beowulf ``recipe'' meet your needs? Will any kind of cluster? In other words...