 | Chapter 9: Log Files |  |

Sometimes it's not that easy writing programs to deal with log files. Instead of nice, easily parseable text lines, some logging mechanisms produce nasty, gnarly binary files with proprietary formats that can't be parsed with a single line of Perl. Luckily, Perl isn't afraid of these miscreants. Let's look at a few approaches we can take when dealing with these files. We're going to look at two different examples of binary logs: Unix's wtmp file and NT/2000's event logs.
Back in Chapter 3, "User Accounts", we touched briefly on the notion of logging in and logging out of a Unix host. Login and logout activity is tracked in a file called wtmp on most Unix variants. It is common to check this file whenever there is a question about a user's connection habits (e.g., from what hosts does this person usually log in?).
On NT/2000, the event logs play a more generalized role. They are used as a central clearinghouse for logging practically all activity that takes place on these machines including login and logout activity, OS messages, security events, etc. Their role is analogous to the Unix syslog service we mentioned earlier.
Perl has a function called unpack( ) especially designed to parse binary and structured data. Let's take a look at how we might use it to deal with the wtmp files. The format of wtmp differs from Unix variant to Unix variant. For this specific example we'll look at the wtmp files found on SunOS 4.1.4 and Digital Unix 4.0 because they are pretty simple. Here's a plain text translation of the first three records in a SunOS 4.1.4 wtmp file:
0000000 ~ \0 \0 \0 \0 \0 \0 \0 r e b o o t \0 \0 0000020 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 0000040 , / ; 4 c o n s o l e \0 r o o t 0000060 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 0000100 \0 \0 \0 \0 , / ; 203 c o n s o l e \0 0000120 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 0000140 \0 \0 \0 \0 \0 \0 \0 \0 , / < 230
Unless you are already familiar with the structure of this file, that "ASCII dump" (as it is called) of the data looks like line noise or some other kind of semi-random garbage. So how do we become acquainted with this file's structure?
The easiest way to understand the format of this file is to look at the source code for programs that read and write to it. If you are not literate in the C language, this may seem like a daunting task. Luckily, we don't actually have to understand or even look at most of the source code; we can just examine the portion that defines the file format.
All of the operating system programs that read and write to the wtmp file get their file definition from a single, short C include file, which is very likely to be found at /usr/include/utmp.h. The part of the file we need to look at begins with a definition of the C data structure that will be used to hold the information. If you search for structutmp{ you'll find the portion we need. The next lines after struct utmp{ define each of the fields in this structure. These lines should be each be commented using the /* text */ C comment convention.
Just to give you an idea of how different two versions of wtmp can be, compare the relevant excerpts from utmp.h on these two operating systems.
SunOS 4.1.4:
struct utmp {
char ut_line[8]; /* tty name */
char ut_name[8]; /* user id */
char ut_host[16]; /* host name, if remote */
long ut_time; /* time on */
};
Digital Unix 4.0:
struct utmp {
char ut_user[32]; /* User login name */
char ut_id[14]; /* /etc/inittab id- IDENT_LEN in init */
char ut_line[32]; /* device name (console, lnxx) */
short ut_type; /* type of entry */
pid_t ut_pid; /* process id */
struct exit_status {
short e_termination; /* Process termination status */
short e_exit; /* Process exit status */
} ut_exit; /* The exit status of a process
* marked as DEAD_PROCESS.
*/
time_t ut_time; /* time entry was made */
char ut_host[64]; /* host name same as MAXHOSTNAMELEN */
};
These files provide all of the clues we need to compose the necessary unpack( ) statement. unpack( ) takes a data format template as its first argument. It uses this template to determine how to disassemble the (usually) binary data it receives in its second argument. unpack( ) will take apart the data as instructed, returning a list where each element of the list corresponds to an element of your template.
Let's construct our template piece by piece based on the C structure from the SunOS utmp.h include file above. There are many possible template letters we can use. I've translated the ones we'll use below, but you should check the pack( ) section of the perlfunc manual page for more information. Constructing these templates is not always straightforward; C compilers occasionally pad values out to satisfy alignment constraints. The command pstruct that ships with Perl can often help with quirks likes these.
We do not have any of these complications with our data format. Table 9-1 gives the utmp.h breakdown.
|
C Code |
unpack( ) Template |
Template Letter/Repeat # Translation |
|---|---|---|
|
char ut_line[8]; |
A8 |
ASCII string (space padded), 8 bytes long |
|
char ut_name[8]; |
A8 |
ASCII string (space padded), 8 bytes long |
|
char ut_host[16]; |
A16 |
ASCII string (space padded), 16 bytes long |
|
long ut_time; |
l |
A signed "long" value (may not be the same as the size of a "long" value on a particular machine) |
Having constructed our template, let's use it in a real piece of code:
# this is the template we're going to feed to unpack( )
$template = "A8 A8 A16 l";
# this uses pack( ) to help us determine the size (in bytes)
# of a single record
$recordsize = length(pack($template,( )));
# open the file
open(WTMP,"/var/adm/wtmp") or die "Unable to open wtmp:$!\n";
# read it in one record at a time
while (read(WTMP,$record,$recordsize)) {
# unpack it, using our template
($tty,$name,$host,$time)=unpack($template,$record);
# handle the records with a null character specially
# (see below)
if ($name and substr($name,0,1) ne "\0"){
print "$tty:$name:$host:" ,
scalar localtime($time),"\n";
}
else {
print "$tty:(logout):(logout):",
scalar localtime($time),"\n";
}
}
# close the file
close(WTMP);
Here's the output of this little program:
~:reboot::Mon Nov 17 15:24:30 1997 :0:dnb::0:Mon Nov 17 15:35:08 1997 ttyp8:user:host.mcs.anl.go:Mon Nov 17 18:09:49 1997 ttyp6:dnb:limbo-114.ccs.ne:Mon Nov 17 19:03:44 1997 ttyp6:(logout):(logout):Mon Nov 17 19:26:26 1997 ttyp1:dnb:traal-22.ccs.neu:Mon Nov 17 23:47:18 1997 ttyp1:(logout):(logout):Tue Nov 18 00:39:51 1997
Here are two small comments on the code:
Under SunOS, logouts from a particular tty are marked with a null character in the first position, hence:
if ($name and substr($name,1,1) ne "\0"){
read( ) takes a number of bytes to read as its third argument. Rather than hardcode in a record size like "32", we use a handy property of the pack( ) function. When handed an empty list, pack( ) returns a null or space-padded string the size of a record. This allows us to feed pack( ) an arbitrary record template and have it tell us how big a record is:
$recordsize = length(pack($template,( )));
Groveling through wtmp files on systems is such a common task that Unix systems ship a command for printing a human readable dump of the binary file called last. Here's some sample output showing approximately the same data as the output of our previous example:
dnb ttyp6 traal-22.ccs.neu Mon Nov 17 23:47 - 00:39 (00:52) dnb ttyp1 traal-22.ccs.neu Mon Nov 17 23:47 - 00:39 (00:52) dnb ttyp6 limbo-114.ccs.ne Mon Nov 17 19:03 - 19:26 (00:22) user ttyp8 host.mcs.anl.go Mon Nov 17 18:09 - crash (27+11:50) dnb :0 :0 Mon Nov 17 15:35 - 17:35 (4+02:00) reboot ~ Mon Nov 17 15:24
We can easily call binaries like last from Perl. This code will show all of the unique user names found in our current wtmp file:
# location of the last command binary
$lastexec = "/usr/ucb/last";
open(LAST,"$lastexec|") or die "Unable to run $lastexec:$!\n";
while(<LAST>){
$user = (split)[0];
print "$user","\n" unless exists $seen{$user};
$seen{$user}='';
}
close(LAST) or die "Unable to properly close pipe:$!\n";
So why use this method when unpack( ) looks like it can serve all of your needs? Portability. As we've shown, the format of the wtmp file differs from Unix variant to Unix variant. On top of this, a vendor can change the format of wtmp between OS releases, rendering your perfectly good unpack( ) template invalid.
However, one thing you can reasonably depend on is the continued presence of a last command that will read this format, independent of any underlying format changes. If you use the unpack( ) method, you have to create and maintain separate template strings for each different wtmp format you plan to parse.[1]
[1]There's a bit of handwaving here, since you still have to track where the last executable is found in each Unix environment and compensate for any differences in the format of each program's output.
The biggest disadvantage of using this method over unpack( ) is the increased sophistication of the field parsing you need to do in the program. With unpack( ), all of the fields are automatically extracted from the data for you. Using our last example, you may find yourself with split( ) or regular-expression-resistant output like this, all in the same output:
user console Wed Oct 14 20:35 - 20:37 (00:01) user pts/12 208.243.191.21 Wed Oct 14 09:19 - 18:12 (08:53) user pts/17 208.243.191.21 Tue Oct 13 13:36 - 17:09 (03:33) reboot system boot Tue Oct 6 14:13
Your eye has little trouble picking out the columns, but any program that parses this output will have to deal with the missing information in lines one and four. unpack( ) can still be used to tease apart this output because it has fixed field widths, but that's not always possible.
For this approach, let's switch our focus to Windows NT/2000's Event Log Service. As we mentioned before, it unfortunately does not log to plain text files. The best, and only, supported way to get to the data is through a set of special API calls. Most users rely on the Event Viewer program, shown in Figure 9-1, to retrieve this data for them.
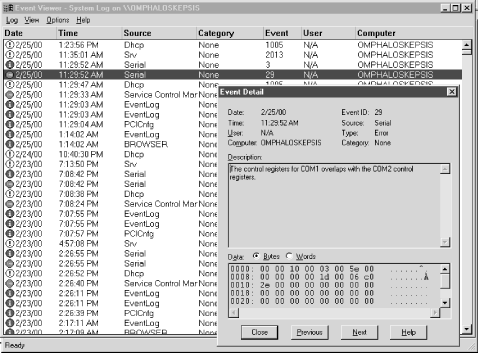
Luckily, there is a Perl module written by Jesse Dougherty (updated by Martin Pauley and Bret Giddings) that allows easy access to the Event Log API calls.[2] Here's a simple program that just dumps a listing of events in the System event log in a syslog-like format. We'll walk through a more complex version of this program later in this chapter.
[2]Log information in Windows 2000 can also be retrieved using the Window Management Instrumentation (WMI) framework we touched on in Chapter 4, "User Activity". Win32::EventLog is easier to use and understand.
use Win32::EventLog;
# each event has a type, this is a translation of the common types
%type = (1 => "ERROR",
2 => "WARNING",
4 => "INFORMATION",
8 => "AUDIT_SUCCESS",
16 => "AUDIT_FAILURE");
# if this is set, we also retrieve the full text of every
# message on each Read( )
$Win32::EventLog::GetMessageText = 1;
# open the System event log
$log = new Win32::EventLog("System")
or die "Unable to open system log:$^E\n";
# read through it one record at a time, starting with the first entry
while ($log->Read((EVENTLOG_SEQUENTIAL_READ|EVENTLOG_FORWARDS_READ),
1,$entry)){
print scalar localtime($entry->{TimeGenerated})." ";
print $entry->{Computer}."[".($entry->{EventID} &
0xffff)."] ";
print $entry->{Source}.":".$type{$entry->{EventType}};
print $entry->{Message};
}
Command-line utilities like last that dump event logs into plain ASCII format also exist for NT/2000. We'll see one of these utilities in action later in this chapter.
|  | |
| 9.1. Text Logs |  | 9.3. Stateful and Stateless Data |

Copyright © 2001 O'Reilly & Associates. All rights reserved.