|
|
We will outline a compiler of DSR to a very limited subset of C (“pseudo-assembly”). The reader should be able to implement this compiler in Caml by filling in the holes we have left out. The compiler uses a series of program transformations to express the compilation process. These program transformations map DSR programs to equivalent DSR programs, removing high-level features one at a time. In particular the following transformations are performed in turn on a DSR program by our compiler:
After a program has gone through these transformations, we have a DSR program that is getting close to the structure of machine language. The last step is then the translate of this primitive DSR program to C.
Real production compilers such as gcc and Sun’s javac do not use a transformation process, primarily because the speed of the compilation itself is too slow. It is in fact possible to produce very good code by transformation. The SML/NJ ML compiler uses a transformational approach [4]. Also, most production compilers transform the program to an intermediate form which is neither source nor target language (“intermediate language”) and do numerous optimizing transformations on this intermediate code. Several textbooks cover compiler technology in detail [5, 3].
Our main goal, unlike a production compiler, is understanding: to appreciate the gap between high- and low-level code, and how the gaps may be bridged. Each transformation that we define bridges one gap. Program transformations are interesting in their own right, as they give insights into the DSR language. Optimization, although a central topic in compilation, is beyond the scope of this book. Our focus is on the compilation of higher-order languages, not C/C++; some of the issues are the same but others are different. Also, our executables will not try to catch run-time type errors or garbage collect unused memory.
The desired soundness property for each DSR program translation is: programs before and after translation have the same execution behavior (in our case, termination and same numerical output, but in general the same I/O behavior). Note that the programs that are output by the translation are not necessarily operationally equivalent to the originals.
The DSR transformations are now covered in the order they are applied to the source program.
Closure conversion is a transformation which eliminates nonlocal variables in functions. For example, x in Function y -> x * y is a nonlocal variable: it is not the parameter and is used in the body. Via closure conversion, all such nonlocal variables can be removed, obtaining an equivalent program where all variables used in functions are parameters of the function. C and C++ have global variables (as does Java via static fields), but global variables are not problematic nonlocal variables. The problematic ones which must be removed are those that are parameters to other functions, where function definitions have been nested. C and C++ have no such problematic nonlocal variables since function definitions cannot be nested. In Java, inner classes are nested class definitions, and there is also an issue of nonlocal variables which must be addressed in Java compilation.
Consider for example the following curried addition function.
add = Function x -> Function y -> x + y
In the body x + y of the inner Function y, x is a nonlocal and y is a local variable for that function.Now, we ask the question, what should add 3 return? Let us consider some obvious choices:
Since neither of these ideas work, something new is needed. The solution is to return a closure, a pair consisting of the function and an environment which remembers the values of any nonlocal variables for later use:
(Function y -> x + y, { x |-> 3 })
Function definitions are now closure definitions; to invoke such a function a new process is needed. Closure conversion is a global program transformation that explicitly performs this operation in the language itself. Function values are defined to be closures, i.e. tuples of the function and an environment remembering the values of nonlocal variables. When invoking a function which is defined as a closure, we must explicitly pass it the nonlocals environment which is in the closure so it can be used find values of the nonlocals.
The translation is introduced by way of example. Consider the inner Function y -> x + y in add above translates to the closure
| { fn = Function yy -> (yy.envt.x) + (yy.arg); |
| envt = { x = xx.arg } }; |
Let us look at the details of the translation. Closures are defined as tuples in the form of records
{ fn = Function ...; envt = {x = ...; ...}}
consisting of the original function (the fn field) and the nonlocals environment (the envt field), which is itself a record. In the nonlocals environment { x = xx.arg }, x was a nonlocal variable in the original function, and its value is remembered in this record using a label of the same name, x. All such nonlocal variables are placed in the environment; in this example x is the only nonlocal variable.
Functions that used to take an argument y are modified to take an argument named yy (the original variable name, doubled up). We don’t really have to change the name but it helps in understanding because the role of the variable has changed: the new argument yy is expected to be a record of the form { envt = ..; arg = ..}, passing both the environment and the original argument to the function.
If yy is indeed such a record at function invocation, then within the body we can use yy.envt.x to access what was a nonlocal variable x in the original function body, and yy.arg to access what was the argument y to the function.
The whole add function is closure-converted by converting both functions:
| add' = { |
| fn = Function xx -> { |
| fn = Function yy -> (yy.envt.x) + (yy.arg); |
| envt = { x = xx.arg } |
| }; |
| envt = {} |
| } |
The outer Function x -> ... arguably didn’t need to be closure-converted since it had no nonlocals, but for uniformity it is best to closure convert all functions.
Translation of function application In the above example, there were no applications, and so we didn’t define how closure-converted functions are to be applied. Application must change, because functions are now in fact represented as records. Function call add 3 after closure conversion then must pass in the environment since the caller needs to know it:
(add'.fn)({ envt = add'.envt; arg = 3})
So, we first pull out the function part of the closure, (add'.fn), and then pass it a record consisting of the environment add'.envt also pulled from the closure, and the argument, 3. Translation of add 3 4 takes the result of the above, which should evaluate to a function closure { fn = ...; envt = ...}, and does the same trick to apply 4 to it:
| Let add3' = (add'.fn){ envt = add'.envt; arg = 3 } In |
| (add3'.fn){ envt = add3'.envt; arg = 4} |
and the result would be 12, the same as the original result, confirming the soundness of the translation in this case. In general applications are converted as follows. At function call time, the remembered environment in the closure is passed to the function in the closure. Thus, for the add' 3 closure above, add3', when it is applied later to e.g. 7, the envt will know it is 3 that is to be added to 7.
One more level of nesting Closure conversion is even slightly more complicated if we consider one more level of nesting of function definitions, for example
triadd = Function x -> Function y -> Function z -> x + y + z
The Function z needs to get x, and since that Function z is defined inside Function y, Function y has to be an intermediary to pass from the outermost function x. Here is the translation.
| triadd' = { |
| fn = Function xx -> { |
| fn = Function yy -> { |
| fn = Function zz -> |
| (zz.envt.x) + (zz.envt.x) + (zz.arg); |
| envt = { x = yy.envt.x; y = yy.arg } |
| }; |
| envt = { x = xx.arg } |
| }; |
| envt = {} |
| } |
Some observations can be made. The inner z function has nonlocals x and y so both of them need to be in its environment; The y function doesn’t directly use nonlocals, but it has nonlocal x because the function inside it, Function z, needs x. So its nonlocals envt has x in it. Function z can get x into its environment from y’s environment, as yy.envt.x. Thus, Function y serves as middleman to get x to Function z.
With the previous example in mind, we can write out the official closure conversion translation. We will use the notation clconv(e) to express the closure conversion function, defined inductively as follows (this code is informal; it uses concrete DSR syntax which in the case of e.g. records looks like Caml syntax).
| { fn = Function xx -> SUB[clconv(e)]; |
| envt = { x1 = x1; ...; xn = xn } } |
where SUB[clconv(e)] is clconv(e) with substitutions (xx.envt.x1)/x1, ..., (xx.envt.xn)/xn and (xx.arg)/x performed on it, but not substituting in Function’s inside clconv(e) (stop substituting when you hit a Function).
For the above example, clconv(add) is add'. The desired soundness result is
Theorem 7.1. Expression e computes to a value if and only if clconv(e) computes to a value. Additionally, if one returns numerical value n, the other returns the same numerical value n.
Closure conversion produces programs where functions have no nonlocal variables, and all functions thus could have been defined at the “top level” like in C. In fact, in Section 7.3 below we will explicitly hoist all inner function definitions out to the top.
Machine language programs are linear sequences of atomic instructions; at most one arithmetic operation is possible per instruction, so many instructions are needed to evaluate complex arithmetic (and other) expressions. The A-translation closes the gap between expression-based programs and linear, atomic instructions, by rephrasing expression-based programs as a sequence of atomic operations. We represent this as a sequence of Let statements, each of which performs one atomic operation.
The idea should be self-evident from the case of arithmetic expressions. Consider for instance
4 + (2 * (3 + 2))
Our DSR interpreter defined a tree-notion of evaluation order on such expressions. The order in which evaluation happens on this program can be made explicitly linear by using Let to factor out the parts in the order that the interpreter evaluates the program
| Let v1 = 3 + 2 In |
| Let v2 = 2 * v1 In |
| Let v3 = 4 + v2 In |
| v3 |
This program should give the same result as the original since all we did was to make the computation sequence more self-evident. Notice how similar this is to 3-address machine code: it is a linear sequence of atomic operations directly applied to variables or constants. The v1 etc variables are temporaries; in machine code they generally end up being assigned to registers. These temporaries are not re-used (re-assigned to) above. Register-like programming is not possible in DSR but it is how real 3-address intermediate language works. In the final machine code generation temporaries are re-used (via a register allocation strategy).
We are in fact going to use a more naive (but uniform) translation, that also first assigns constants and variables to other variables:
| Let v1 = 4 In |
| Let v2 = 2 In |
| Let v3 = 3 In |
| Let v4 = 2 In |
| Let v5 = v3 + v4 In |
| Let v6 = v2 * v5 In |
| Let v7 = v1 + v6 In |
| v7 |
This simple translation closely corresponds to the operational semantics--every node in a derivation of e ==> v is a Let in the above.
Exercise 7.1. Write out the operational semantics derivation and compare its structure to the above.
This translation has the advantage that every operation will be between variables. In the previous example above, 4+v2 may not be low-level enough for some machine languages since there may be no add immediate instruction. One simple optimization would be to avoid making fresh variables for constants. Our emphasis at this point is on correctness as opposed to efficiency, however. Let is a primitive in DSR--this is not strictly necessary, but if Let were defined in terms of application, the A-translation results would be harder to manipulate.
Next consider DSR code that uses higher-order functions.
((Function x -> Function y -> y)(4))(2)
The function to which 2 is being applied first needs to be computed. We can make this explicit via Let as well:
| Let v1 = (Function x -> Function y -> y)(4) In |
| Let v2 = v1(2) In |
| x |
The full A-translation will, as with the arithmetic example, do a full linearization of all operations:
| Let v1 = |
| (Function x -> |
| Let v1' = (Function y -> Let v1'' = y in v1'') In v1') |
| In |
| Let v2 = 4 In |
| Let v3 = v1 v2 In |
| Let v4 = 2 In |
| Let v5 = v3 v4 In |
| v5 |
All forms of DSR expression can be linearized in similar fashion, except If:
If (3 = x + 2) Then 3 Else 2 * x
can be transformed into something like
| Let v1 = x + 2 In |
| Let v2 = (3 = v1) In |
| If v2 Then 3 Else Let v1 = 2 * x In v1 |
but the If still has a branch in it which cannot be linearized. Branches in machine code can be linearized via labels and jumps, a form of expression lacking in DSR. The above transformed example is still “close enough” to machine code: we can implement it as
| v1 := x + 2 |
| v2 := 3 = v1 |
| BRANCH v2, L2 |
| L1: v3 := 3 |
| GOTO L3 |
| L2: v4 := 4 |
| L3: |
We define the A-translation as a Caml function, atrans(e) : term -> term. We will always apply A-translation to the result of closure conversion, but that fact is irrelevant for now.
The intermediate result of A-translation is a list of tuples
[(v1,e1); ...; (vn,en)] : (ide * term) list
which is intended to represent
Let v1 = e1 In ... In Let vn = en In vn ...
but is a form easier to manipulate in Caml since lists of declarations will be appended together at translation time. When writing a compiler, the programmer may or may not want to use this intermediate form. It is not much harder to write the functions to work directly on the Let representation.
We now sketch the translation for the core primitives. Assume the following auxiliary functions have been defined:
At the end of the A-translation, the code is all “linear” in the way it runs in the interpreter, not as a tree. Machine code is also linearly ordered; we are getting much closer to machine code.
Theorem 7.2. A-translation is sound, i.e. e and atrans(e) both either compute to values or both diverge.
Although we have only partially defined A-translation, the extra syntax of DSR (records, reference cells) does not provide any major complication.
So far, we have defined a front end of a compiler which performs closure conversion and A-translation in turn:
let atrans_clconv e = atrans(clconv(e))
After these two phases, functions will have no nonlocal variables. Thus, we can hoist all functions in the program body to the start of the program. This brings the program structure more in line with C (and machine) code. Since our final target is C, the leftover code from which all functions were hoisted then is made the main function. A function hoist carries out this transformation. Informally, the operation is quite simple: take e.g.
4 + (Function x -> x + 1)(4)
and replace it by
Let f1 = Function x -> x + 1 In 4 + f1(4)
In general, we hoist all functions to the front of the code and give them a name via Let. The transformation is always sound if there are no free variables in the function body, a property guaranteed by closure conversion. We will define this process in a simple iterative (but inefficient) manner:
| let hoist e = |
| if e = e1[(Function ea -> e')/f] for some e1 with f free, |
| and e' itself contains no functions |
| (i.e. Function ea -> e' is an innermost function) |
| then |
| Let f = (Function ea -> e') In hoist(e1) |
| else e |
This function hoists out innermost functions first. If functions are not hoisted out innermost-first, there will still be some nested functions in the hoisted definitions. So, the order of hoisting is important.
The definition of hoisting given above is concise, but it is too inefficient. A one-pass implementation can be used that recursively replaces functions with variables and accumulates them in a list. This implementation is left as an exercise. Resulting programs will be of the form
| Let f1 = Function x1 -> e1 In |
| ... |
| Let fn = Function xn -> en In |
| e |
where each e,e1,...en contain no function constants.
Theorem 7.3. If all functions occurring in expression e contain no nonlocal variables, then e =~hoist(e).
This Theorem may be proved by iterative application of the following Lemma:
| e1[(Function x -> e')/f] =~ |
| (Let f = (Function x -> e') In e1 |
provided e' contains at most the variable x free.
We lastly transform the program to
| Let f1 = Function x1 -> e1 In |
| ... |
| fn = Function -> Function xn -> en In |
| main = Function dummy -> e In |
| main(0) |
So, the program is almost nothing but a collection of functions, with a body that just invokes main. This brings the program closer to C programs, which are nothing but a collection of functions and main is implicitly invoked at program start.
Let Rec definitions also need to be hoisted to the top level; their treatment is similar and will be left as an exercise.
We are now ready to translate into C. To summarize up to now, we have
let hoist_atrans_clconv e = hoist(atrans(clconv(e)))
We have done about all the translation that is possible within DSR. Programs are indeed looking a lot more like machine code: all functions are declared at the top level, and each function body consists of a linear sequence of atomic instructions (with exception of If which is a branch). There still are a few things that are more complex than machine code: records are still implicitly allocated, and function call is atomic, no pushing of parameters is needed. Since C has function call built in, records are the only significant gap that needs to be closed.
The translation involves two main operations.
Atomic Tuples Before giving the translation, we enumerate all possible right-hand sides of Let variable assignments that come out of the A-translation (in the following vi, vj, vk, and f are variables).These are called the atomic tuples.
Fact 7.1 (Atomic Tuples). DSR programs that have passed through the first three phases have function bodies consisting of tuple lists where each tuple is of one of the following forms only:
Functions should have all been hoisted to the top so there will be none of those in the tuples. Observe that some of the records usages are from the original program, and others were added by the closure conversion process. We can view all of them as regular records. All we need to do now is generate code for each of the above tuples.
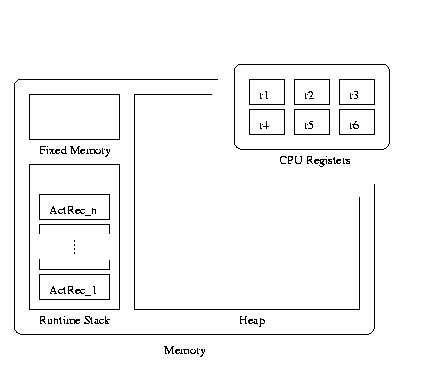
Before writing any compiler, a fixed memory layout scheme for objects at run-time is needed. Since objects can be read and written from many different program points, if read and write protocols are not uniform for a given object, the code simply will not work! So, it is very important to carefully design the strategy beforehand. Simple compilers such as ours will use simple schemes, but for efficiency it is better to use a more complex scheme.
Lets consider briefly how memory is laid out in C. Values can be stored in several different ways:
Figure 7.1 illustrates the overall model of memory we are dealing with.
To elaborate a bit more on stack storage of variables, here is some C pseudo-code to give you the idea of how the stack pointer sp is used.
Stack-stored entities are also temporary in that they will be junk when the function/method returns.
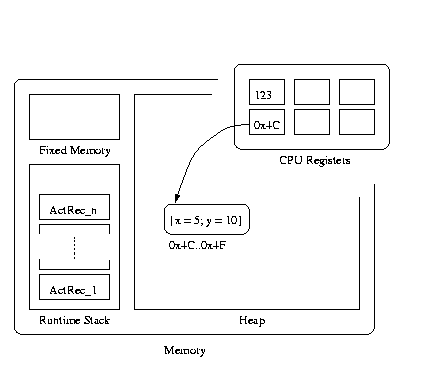
Another important issue is whether to box or unbox values.
Definition 7.4. A register or memory location vi’s value is stored boxed if vi holds a pointer to a block of memory containing the actual value. A variable’s value is unboxed if it is directly in the register or memory location v1.
Figure 7.2 illustrates the difference between boxed and unboxed values.
|
|
For multi-word entities such as arrays, storing them unboxed means variables directly hold a pointer to the first word of the sequence of space. To clarify the above concepts we review C’s memory layout convention. Variables may be declared either as globals, register (the register directive is a request to put in a register only), or on the call stack; all variables declared inside a function are kept on the stack. Variables directly holding ints, floats, structs, and arrays are all unboxed. (Examples: int x; float x; int arr[10]; snork x for snork a struct.) There is no such thing as a variable directly holding a function; variables in C may only hold pointers to functions. It is possible to write “v = f” in C where f is a previously declared function and not “v = &f”, but that is because the former is really syntactic sugar for the latter. A pointer to a function is in fact a pointer to the start of the code of the function. Boxed variables in C are declared explicitly, as pointer variables. (Examples: int *x; float *x; int *arr[10]; snork *x for snork a struct.) All malloc’ed structures must be stored in a pointer variable because they are boxed: variables can’t directly be heap entities. Variables are static and the heap is dynamic.
Here is an example of a simple C program and the Sun SPARC assembly output which gives some impressionistic idea of these concepts:
| int glob; |
| main() |
| { |
| int x; |
| register int reg; |
| int* mall; |
| int arr[10]; |
| x = glob + 1; |
| reg = x; |
| mall = (int *) malloc(1); |
| x = *mall; |
| arr[2] = 4; |
| /* arr = arr2; --illegal: arrays are not boxed */ |
| } |
In the assembly language, %o1 is a register, [%o0] means dereference, [%fp-24] means subtract 24 from frame pointer register %fp and dereference. The assembly representation of the above C code is as follows.
Our memory layout strategy is more like a higher-level language such as Java or ML. The Java JVM uses a particular, fixed, memory layout scheme: all object references are boxed pointers to heap locations; the primitive bool, byte, char, short, int, long, float, and double types are kept unboxed. Since Java arrays are objects they are also kept boxed. There is no reference (&) or dereference (*) operator in Java. These operations occur implicitly.
Memory layout for our DSR compiler DSR is (mostly) a Caml subset and so its memory is also managed more implicitly than C memory. We will use a simple, uniform scheme in our compilers which is close in spirit to Java’s: Box Refs and records and function values, but keep boolean values and integers unboxed. Also, as in C (and Java), all local function variables will be allocated on the stack and accessed as offsets from the stack pointer. We will achieve the latter by implementing DSR local variables as C local variables, which will be stack allocated by the C compiler. Since a Ref is nothing but a mutable location, there may not seem to be any reason to box it. However, if a function returns a Ref as result, and it were not boxed, it would have been allocated on the stack and thus would be deallocated. Here is an example that reflects this problem:
Let f = (Function x -> Ref 5) In !f(_) + 1
If Ref 5 were stored on the stack, after the return it could be wiped out. All of the Let-defined entities in our tuples (the vi variables) can be either in registers or on the call stack: none of those variables are directly used outside the function due to lexical scoping, and they don’t directly contain values that should stay alive after the function returns. For efficiency, they can all be declared as register Word variables:
register Word v1, v2, v3, v4, ...;
One other advantage of this simple scheme is every variable holds one word of data, and thus we don’t need to keep track of how much data a variable is holding. This scheme is not very efficient, and real compilers optimize significantly. One example is Ref’s which are known to not escape a function can unboxed and stack allocated.
All that remains is to come up with a scheme to compile each of the above atomic tuples and we are done. Records are the most difficult so we will consider them before writing out the full translation.
Compiling untyped records Recall from when we covered records that the fields present in a record cannot be known in advance if there is no type system. So, we won’t know where the field that we need is exactly. Consider, for example,
(Function x -> x.l)(If y = 0 Then {l = 3} Else {a = 4; l = 3})
Field l will be in two different positions in these records so the selection will not have a sole place it can find the field in. Thus we will need to use a hashtable for record lookup. In a typed language such as Caml this problem is avoided: the above code is not well-typed in Caml because the if-then can’t be typed. Note that the problems with records are closely related to problems with objects, since objects are simply records with Refs.This memory layout difficulty with records illustrates an important relationship between typing and compilation. Type systems impose constraints on program structure that can make compilers easier to implement. Additionally, typecheckers will obviate the need to deal with certain run-time errors. Our simple DSR compilers are going to core dump on e.g. 4 (5); in Lisp, Smalltalk, or Scheme these errors would be caught at run-time but would slow down execution. In a typed language, the compiler would reject the program since it will not typecheck. Thus for typed languages they will both be faster and safer.
Our method for compilation of records proceeds as follows. We must give records a heavy implementation, as hash tables (i.e., a set of key-value pairs, where the keys are label names). In order to make the implementation simple, records are boxed so they take one word of memory, as mentioned above when we covered boxing. A record selection operation vk.l is implemented by hashing on key l in the hash table pointed to by vk at runtime. This is more or less how Smalltalk message sends are implemented, since records are similar to objects (and Smalltalk is untyped).
The above is less than optimal because space will be needed for the hashtable, and record field accessing will be much slower than, for example, struct access in C. Since closures are records, this will also significantly slow down function call. A simple optimization would be to treat closure records specially since the field positions will always be fixed, and use a struct implementation of closure (create a different struct type for each function).
For instance, consider
(Function x -> x.l)(If y = 0 Then {l = 3} Else {a = 4; l = 3})
The code x.l will invoke a call of approximate form hashlookup(x,"l"). {a = 4; l = 3} will create a new hash table and add mappings of "a" to 4 and "l" to 3.
We are now ready to write the final translation to C, via functions
The translation as informally written below takes a few liberties for simplicity. Strings "..." below are written in shorthand. For instance "vi = x" is shorthand for tostring(vi) ^" = " ^tostring(x). The tuples Let x1 = e1 In Let ...In Let xn = en In xn of function and then/else bodies are assumed to have been converted to lists of tuples [(x1,e1),...,(xn,en)], and similarly for the list of top-level function definitions. When writing a compiler, it probably will be easier just to simply keep them in Let form, although either strategy will work.
The reader may wonder why a fresh memory location is allocated for a Ref, as opposed to simply storing the existing address of the object being referenced. This is a subtle issue, but the code vi = &vj, for example, would definitely not work for the Ref case (vj may go out of scope).
This translation sketch above leaves out many details. Here is some elaboration.
Typing issues We designed out memory layout so that every entity takes up one word. So, every variable is of some type that is one word in size. Type all variables as Word’s, where Word is a 1-word type (defined as e.g. typedef void *Word;). Many type casts need to be inserted; we are basically turning off the type-checking of C, but there is no ”switch” that can be flicked. So, for instance vi = vj + vk will really be vi = (Word (int vj) + (int vk)) - cast the words to ints, do the addition, and cast back to a word. To cast to a function pointer is a tongue-twister: in C you can use (*((Word (*)()) f))(arg). The simplest way to avoid confusion when actually writing a compiler is to include the following typedefs to the resulting C code:
Global Issues Some global issues you will need to deal with include the following. You will need to print out the result returned by the main function (so, you probably want the DSR main function to be called something like DSRmain and then write your own main() by hand which will call DSRmain); The C functions need to declare all the temporary variables they use. One solution is to declare in the function header a C array
Word v[22]
where 22 is the number of temporaries needed in this particular function, and use names v[0], v[1], etc for the temporaries. Note, this works well only if the newid() function is instructed to start numbering temporaries at zero again upon compiling each new function. Every compiled program is going to have to come with a standard block of C code in the header, including the record hash implementation, main() as alluded to above, etc.Other issues that present problems include the following. Record creation is only sketched; but there are many C hash set libraries that could be used for this purpose. The final result (resultId) of the Then and Else tuples needs to be in the same variable vi, which is also the variable where the result of the tuple is put, for the If code to be correct. This is best handled in the A-translation phase.
There are several other issues that will arise when writing the compiler. The full implementation is left as an exercise.
Now that we have covered the compilation to C, we informally consider how a compiler would compile all the way to machine code. The C code we produce above is very close to assembly code. It would be conceptually easy to translate into assembly, but we skip the topic due to the large number of cases that arise in the process (saving registers, allocating space on the stack for temporaries.
| let frontend e = hoist(atrans(clconv(e)));; |
| let translator e = toC(frontend(e));; |
We can assert the correctness of our translator.
Theorem 7.4. DSR program e terminates in the DSR operational semantics (or evaluator) just when the C program translator(e) terminates, provided the C program does not run out of memory. Core dump or other run-time errors are equated with nontermination. Furthermore, if DSR’s eval(e) returns a number n, the compiled translator(e) will also produce numerical output n.
Optimization can be done at all phases of the translation process. The above translation is simple, but inefficient. There is always a tradeoff between simplicity and efficiency in compiler designs, both the efficiency of compilation itself, and efficiency of code produced. In the phases before C code is produced, optimizations consist of replacing chunks of the program with operationally equivalent chunks.
Some simple optimizations include the following. The special closure records {fn = .., envt = .. } could be implemented as a pointer to a C struct with fn and envt fields, instead of using the very slow hash method,1 will significantly speed up the code produced. Records which do not not have field names overlapping with other records can also be implemented in this manner (there can be two different records with the same fields, but not two different records with some fields the same and some different). Another optimization is to modify the A-translation to avoid making tuples for variables and constants. Constant expressions such as 3 + 4 can be folded to 7.
More fancy optimizations require a global flow analysis be performed. Simply put, a flow analysis finds all possible uses of a particular definition, and all possible definitions corresponding to a particular use.
A definition is a record, a Function, or a number or boolean, and a use is a record field selection, function application, or numerical or boolean operator.
Our compiled code mallocs but never frees. We will eventually run out of memory. A garbage collector is needed.
Definition: In a run-time image, memory location n is garbage if it never will be read or written to again.
There are many notions of garbage detection. The most common is to be somewhat more conservative and take garbage to be memory locations which are not pointed to by any known (”root”) object.