
Web Client Programming with Perl
Automating Tasks on the Web
By Clinton Wong1st Edition March 1997
This book is out of print, but it has been made available online through the O'Reilly Open Books Project.
|
|
|
|
|
Web Client Programming with PerlAutomating Tasks on the WebBy Clinton Wong1st Edition March 1997 This book is out of print, but it has been made available online through the O'Reilly Open Books Project. |
Chapter 4.
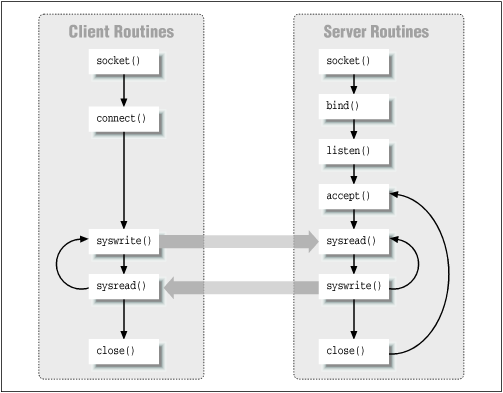
The Socket LibraryThe socket library is a low-level programmer's interface that allows clients to set up a TCP/IP connection and communicate directly to servers. Servers use sockets to listen for incoming connections, and clients use sockets to initiate transactions on the port that the server is listening on.
Do you really need to know about sockets? Possibly not. In Chapter 5, The LWP Library, we cover LWP, a library that includes a simple framework for connecting to and communicating over the Web, making knowledge of the underlying network communication superfluous. If you plan to use LWP you can probably skip this chapter for now (and maybe forever).
Compared to using something like LWP, working with sockets is a tedious undertaking. While it gives you the power to say whatever you want through your network connection, you need to be really careful about what you say; if it's not fully compliant with the HTTP specs, the web server won't understand you! Perhaps your web client works with one web server but not another. Or maybe your web client works most of the time, but not in special cases. Writing a fully compliant application could become a real headache. A programmer's library like LWP will figure out which headers to use, the parameters with each header, and special cases like dealing with HTTP version differences and URL redirections. With the socket library, you do all of this on your own. To some degree, writing a raw client with the socket library is like reinventing the wheel.
However, some people may be forced to use sockets because LWP is unavailable, or because they just prefer to do things by hand (the way some people prefer to make spaghetti sauce from scratch). This chapter covers the socket calls that you can use to establish HTTP connections independently of LWP. At the end of the chapter are some extended examples using sockets that you can model your own programs on.
A Typical Conversation over Sockets
The basic idea behind sockets (as with all TCP-based client/server services) is that the server sits and waits for connections over the network to the port in question. When a client connects to that port, the server accepts the connection and then converses with the client using whatever protocol they agree on (e.g., HTTP, NNTP, SMTP, etc.).
Initially, the server uses the socket( ) system call to create the socket, and the bind( ) call to assign the socket to a particular port on the host. The server then uses the listen( ) and accept( ) routines to establish communication on that port.
On the other end, the client also uses the socket( ) system call to create a socket, and then the connect( ) call to initiate a connection associated with that socket on a specified remote host and port.
The server uses the accept( ) call to intercept the incoming connection and initiate communication with the client. Now the client and server can each use sysread( ) and syswrite( ) calls to speak HTTP, until the transaction is over.
Instead of using sysread( ) and syswrite( ), you can also just read from and write to the socket as you would any other file handle (e.g., print <FH>;).
Finally, either the client or server uses the close( ) or shutdown( ) routine to end the connection.
Figure 4-1 shows the flow of a sockets transaction.
Figure 4-1. Socket calls
Using the Socket Calls
The socket library is part of the standard Perl distribution. Include the socket module like this:
use Socket;Table 4-1 lists the socket calls available using the socket library in Perl.
Table 4-1: Socket Calls Function
Usage
Purpose
socket( )
Both client and server
Create a generic I/O buffer in the operating system
connect( )
Client only
Establish a network connection and associate it with the I/O buffer created by socket( )
sysread( )
Both client and server
Read data from the network connection
syswrite( )
Both client and server
Write data to the network connection
close( )
Both client and server
Terminate communication
bind( )
Server only
Associate a socket buffer with a port on the machine
listen( )
Server only
Wait for incoming connection from a client
accept( )
Server only
Accept the incoming connection from client
Conceptually, think of a socket as a "pipe" between the client and server. Data written to one end of the pipe appears on the other end of the pipe. To create a pipe, call socket( ). To write data into one end of the pipe, call syswrite( ). To read on the other end of the pipe, call sysread( ). Finally, to dispose of the pipe and cease communication between the client and server, call close( ).
Since this book is primarily about client programming, we'll talk about the socket calls used by clients first, followed by the calls that are only used on the server end. Although we're only writing client programs, we cover both client and server functions, for the sake of showing how the library fits together.
Initializing the Socket
Both the client and server use the socket( ) function to create a generic "pipe" or I/O buffer in the operating system. The socket( ) call takes several arguments, specifying which file handle to associate with the socket, what the network protocol is, and whether the socket should be stream-oriented or record-oriented. For HTTP transactions, sockets are stream-oriented connections running TCP over IP, so HTTP-based applications must associate these characteristics with a newly created socket.
For example, in the following line, the SH file handle is associated with the newly created socket. PF_INET indicates the Internet Protocol while getprotobyname('tcp') indicates that the Transmission Control Protocol (TCP) runs on top of IP. Finally, SOCK_STREAM indicates that the socket is stream-oriented, as opposed to record-oriented:
socket(SH, PF_INET, SOCK_STREAM, getprotobyname('tcp')) || die $!;If the socket call fails, the program should die( ) using the error message found in $!.
Establishing a Network Connection
Calling connect( ) attempts to contact a server at a desired host and port. The configuration information is stored in a data structure that is passed to connect( ).
my $sin = sockaddr_in (80,inet_aton('www.ora.com'));connect(SH,$sin) || die $!;The Socket::sockaddr_in( ) routine accepts a port number as the first parameter and a 32-bit IP address as the second number. Socket::inet_aton( ) translates a hostname string or dotted decimal string to a 32-bit IP address. Socket::sockaddr_in( ) returns a data structure that is then passed to connect( ). From there, connect( ) attempts to establish a network connection to the specified server and port. Upon successful connection, it returns true. Otherwise, it returns false upon error and assigns $! with an error message. Use die( ) after connect( ) to stop the program and report any errors.
Writing Data to a Network Connection
To write to the file handle associated with the open socket connection, use the syswrite( ) routine. The first parameter is the file handle to write the data to. The data to write is specified as the second parameter. Finally, the third parameter is the length of the data to write. Like this:
$buffer="hello world!";syswrite(FH, $buffer, length($buffer));An easier way to communicate is with print. When used with an autoflushed file handle, the result is the same as calling syswrite( ). The print command is more flexible than syswrite( ) because the programmer can specify more complex string expressions that are difficult to specify in syswrite( ). Using print, the previous example looks like this:
select(FH);$|=1; # set $| to non-zero to make selection autoflushedprint FH "hello world!";Reading Data From a Network Connection
To read from the file handle associated with the open socket connection, use the sysread( ) routine. In the first parameter, a file handle is given to specify the connection to read from. The second parameter specifies a scalar variable to store the data that was read. Finally, the third parameter specifies the maximum number of bytes you want to read from the connection. The sysread( ) routine returns the number of bytes actually read:
sysread(FH, $buffer, 200); # read at most 200 bytes from FHIf you want to read a line at a time from the file handle, you can also use the angle operator on it, like so:
$buffer = <FH>;Closing the Connection
After the network transaction is complete, close( ) disconnects the network connection.
close(FH);Server Socket Calls
The following functions set the socket in server mode and map a client's incoming request to a file handle. After a client request has been accepted, all subsequent communication with the client is referenced through the file handle with sysread( ) and syswrite( ), as described earlier.
Binding to the Port
A sockets-based server application first creates the socket as follows:
my $proto = getprotobyname('tcp');socket(F, PF_INET, SOCK_STREAM, $proto) || die $!;Next, the program calls bind( ) to associate the socket with a port number on the machine. If another program is already using the port, bind( ) returns a false (zero) value. Here, we use sockaddr_in( ) to identify the port for bind( ). (We use port 80, the traditional port for HTTP.)
my $sin = sockaddr_in(80,INADDR_ANY);bind(F,$sin) || die $!;Waiting for a Connection
The listen( ) function tells the operating system that the server is ready to accept incoming network connections on the port. The first parameter is the file handle of the socket to listen to. In the event that multiple client programs are connecting to the port at the same time, a queue of network connections is maintained by the operating system. The queue length is specified in the second parameter:
listen(F, $length) || die $!;Accepting a Connection
The accept( ) function waits for an incoming request to the server. For parameters, accept( ) uses two file handles. The one we've been dealing with so far is a generic file handle associated with the socket. In the above example code, we've called it F. This is passed in as the second parameter. The first parameter is a file handle that accept( ) will associate with a specific network connection.
accept(FH,F) || die $!;So when a client connects to the server, accept( ) associates the client's connection with the file handle passed in as the first parameter. The second parameter, F, still refers to a generic socket that is connected to the designated port and is not specifically connected to any clients.
You can now read and write to the filehandle to communicate with the client. In this example, the filehandle is FH. For example:
print FH "HTTP/1.0 404 Not Found\n";Client Connection Code
The following Perl function encapsulates all the necessary code needed to establish a network connection to a server. As input, open_TCP( ) requires a file handle as a first parameter, a hostname or dotted decimal IP address as the second parameter, and a port number as the third parameter. Upon successfully connecting to the server, open_TCP( ) returns 1. Otherwise, it returns undef upon error.
############# open_TCP ############### Given ($file_handle, $dest, $port) return 1 if successful, undef when# unsuccessful.## Input: $fileHandle is the name of the filehandle to use# $dest is the name of the destination computer,# either IP address or hostname# $port is the port number## Output: successful network connection in file handle#use Socket;sub open_TCP{# get parametersmy ($FS, $dest, $port) = @_;my $proto = getprotobyname('tcp');socket($FS, PF_INET, SOCK_STREAM, $proto);my $sin = sockaddr_in($port,inet_aton($dest));connect($FS,$sin) || return undef;my $old_fh = select($FS);$| = 1; # don't buffer outputselect($old_fh);1;}1;Using the open_TCP( ) Function
Let's try out the function. In the following code, you will need to include the open_TCP( ) function. You can include it in the same file or put it in another file and use the require directive to include it. If you put it in a separate file and require it, remember to put a "1;" as the last line of the file that is being required. In the following example, we've placed the open_TCP( ) routine into another file (tcp.pl, for lack of imagination), and required it along with the socket library itself:
#!/usr/local/bin/perluse Socket;require "tcp.pl";Once the socket library and open_TCP( ) routine are included, the example below uses open_TCP( ) to establish a connection to port 13 on the local machine:
# connect to daytime server on the machine this client is running onif (open_TCP(F, "localhost", 13) == undef) {print "Error connecting to server\n";exit(-1);}If the local machine is running the daytime server, which most UNIX systems and some NT systems run, open_TCP( ) returns successfully. Then, output from the daytime server is printed:
# if there is any input, echo itprint $_ while (<F>);Then we close the connection.
close(F);After running the program, you should see the local time, for example:
Tue Jun 14 00:03:12 1996This can also be done by using telnet to connect to port 13:
(intense) /homes/apm> telnet localhost 13Trying 127.0.0.1...Connected to localhost.Escape character is '^'.Tue Jun 14 00:03:12 1996Connection closed by foreign host.Your First Web Client
Let's modify the previous code to work with a web server instead of the daytime server. Also, instead of embedding the machine name of the server into the source code, let's modify the code to accept a hostname from the user on the command line. Since port 80 is the standard port that web servers use, we'll use port 80 in the code instead of the daytime server's port:
# contact the serverif (open_TCP(F, $ARGV[0], 80) == undef) {print "Error connecting to server at $ARGV[0]\n";exit(-1);}In the interest of making the program a little more user-friendly, let's add some help text:
# If no parameters were given, print out help textif ($#ARGV) {print "Usage: $0 Ipaddress\n";print "\n Returns the HTTP result code from a server.\n\n";exit(-1);}Instead of connecting to the port and listening for data, the client needs to send a request before data can be retrieved from the server:
print F "GET / HTTP/1.0\n\n";Then the response code is retrieved and printed out:
$ReturnStatus=<F>;print "The server had a response line of: $ReturnStatus\n";After all the modifications, the new code looks like this:
#!/usr/local/bin/perluse Socket;require "tcp.pl";# If no parameters were given, print out help textif ($#ARGV) {print "Usage: $0 Ipaddress\n";print "\n Returns the HTTP result code from a web server.\n\n";exit(-1);}# contact the serverif (open_TCP(F, $ARGV[0], 80) == undef) {print "Error connecting to server at $ARGV[0]\n";exit(-1);}# send the GET method with / as a parameterprint F "GET / HTTP/1.0\n\n";# get the response$return_line=<F>;# print out the responseprint "The server had a response line of: $return_line";close(F);Let's run the program and see the result:
The server had a response line of: HTTP/1.0 200 OKParsing a URL
At the core of every good web client program is the ability to parse a URL into its components. Let's start by defining such a function. (If you plan to use LWP, there's something like this in the URI::URL class, and you can skip the example.)
# Given a full URL, return the scheme, hostname, port, and path# into ($scheme, $hostname, $port, $path). We'll only deal with# HTTP URLs.sub parse_URL {# put URL into variablemy ($URL) = @_;# attempt to parse. Return undef if it didn't parse.(my @parsed =$URL =~ m@(\w+)://([^/:]+)(:\d*)?([^#]*)@) || return undef;# remove colon from port number, even if it wasn't specified in the URLif (defined $parsed[2]) {$parsed[2]=~ s/^://;}# the path is "/" if one wasn't specified$parsed[3]='/' if ($parsed[0]=~/http/i && (length $parsed[3])==0);# if port number was specified, we're donereturn @parsed if (defined $parsed[2]);# otherwise, assume port 80, and then we're done.$parsed[2] = 80;@parsed;}# grab_urls($html_content, %tags) returns an array of links that are# referenced from within html.sub grab_urls {my($data, %tags) = @_;my @urls;# while there are HTML tagsskip_others: while ($data =~ s/<([^>]*)>//) {my $in_brackets=$1;my $key;foreach $key (keys %tags) {if ($in_brackets =~ /^\s*$key\s+/i) { # if tag matches, try parmsif ($in_brackets =~ /\s+$tags{$key}\s*=\s*"([^"]*)"/i) {my $link=$1;$link =~ s/[\n\r]//g; # kill newlines,returns anywhere in urlpush (@urls, $link);next skip_others;}# handle case when url isn't in quotes (ie: <a href=thing>)elsif ($in_brackets =~ /\s+$tags{$key}\s*=\s*([^\s]+)/i) {my $link=$1;$link =~ s/[\n\r]//g; # kill newlines,returns anywhere in urlpush (@urls, $link);next skip_others;}} # if tag matches} # foreach tag} # while there are brackets@urls;}1;Given a full URL, parse_URL( ) will break it up into smaller components. The real work is done with:
# attempt to parse. Return undef if it didn't parse.(my @parsed =$URL =~ m@(\w+)://([^/:]+)(:\d*)?([^#]*)@) || return undef;After this initial parse some of the components need to be cleaned up:
- If an optional port was given, remove the colon from $parsed [2].
- If no document path was given, it becomes "/". For example, "http://www.ora.com" becomes "http://www.ora.com/".
The function returns an array of the different URL components: ($scheme, $hostname, $port, $path). Or undef upon error.
Let's try parse_URL( ) with "http://www.ora.com/index.html" as input:
parse_URL("http://www.ora.com/index.html");The parse_URL( ) routine would return the following array: ('http', 'www.ora.com', 80, '/index.html'). We've saved this routine in a file called web.pl, and we'll use it in examples (with a require 'web.pl' ) in this chapter.
Hypertext UNIX cat
Now that we have a function that parses URLs, let's use it to create a hypertext version of the UNIX cat command, called hcat. (There's an LWP version of this in Chapter 6, Example LWP Programs.)
Basically speaking, this program looks at its command-line arguments for URLs. It prints out the full response for the given URL, including the response code, headers, and entity-body. If the user only wants the response code, he can use the -r option. Similarly, the -H option specifies that only headers are wanted. A -d option prints out only the entity body. One can mix these options, too. For example, if the user only wants the response code and headers, she could use -rH. If no arguments are used, or if the -h option is specified, help text is printed out.
Let's go over the command-line parsing:
# parse command line argumentsgetopts('hHrd');# print out usage if neededif (defined $opt_h || $#ARGV<0) { help(); }# if it wasn't an option, it was a URLwhile($_ = shift @ARGV) {hcat($_, $opt_r, $opt_H, $opt_d);}The call to Getopts( ) indicates that we're interested in the -h, -H, -r, and -d command-line options. When Getopts( ) finds these switches, it sets $opt_* (where * is the switch that was specified), and leaves any "foreign" text back on @ARGV. If the user didn't enter any valid options or a URL, help text is printed. Finally, for any remaining command-line parameters, treat them as URLs and pass them to the hcat( ) routine.
Examples:
Print out response line only:
% hcat -r http://www.ora.comPrint out response line and entity-body, but not the headers:
% hcat -rd http://www.ora.comUse multiple URLs:
% hcat http://www.ora.com http://www.ibm.comBack to the program. Inside of the hcat( ) function, we do some basic URL processing:
# if the URL isn't a full URL, assume that it is a http request$full_url="http://$full_url" if ($full_url !~m/(\w+):\/\/([^\/:]+)(:\d*)?([^#]*)/);# break up URL into meaningful partsmy @the_url = &parse_URL($full_url);Then we send an HTTP request to the server.
# connect to server specified in 1st parameterif (!defined open_TCP('F', $the_url[1], $the_url[2])) {print "Error connecting to web server: $the_url[1]\n";exit(-1);}# request the path of the document to getprint F "GET $the_url[3] HTTP/1.0\n";print F "Accept: */*\n";print F "User-Agent: hcat/1.0\n\n";Now we wait for a response from the server. We read in the response and selectively echo it out, where we look at the $response, $header, and $data variables to see if the user is interested in looking at each part of the reply:
# get the HTTP response linemy $the_response=<F>;print $the_response if ($all || defined $response);# get the header datawhile(<F>=~ m/^(\S+):\s+(.+)/) {print "$1: $2\n" if ($all || defined $header);}# get the entity bodyif ($all || defined $data) {print while (<F>);}The full source code looks like this:
#!/usr/local/bin/perl -w# socket based hypertext version of UNIX catuse strict;use Socket; # include Socket modulerequire 'tcp.pl'; # file with Open_TCP routinerequire 'web.pl'; # file with parseURL routineuse vars qw($opt_h $opt_H $opt_r $opt_d);use Getopt::Std;# parse command line argumentsgetopts('hHrd');# print out usage if neededif (defined $opt_h || $#ARGV<0) { help(); }# if it wasn't an option, it was a URLwhile($_ = shift @ARGV) {hcat($_, $opt_r, $opt_H, $opt_d);}# Subroutine to print out usage informationsub usage {print "usage: $0 -rhHd URL(s)\n";print " -h help\n";print " -r print out response\n";print " -H print out header\n";print " -d print out data\n\n";exit(-1);}# Subroutine to print out help text along with usage informationsub help {print "Hypertext cat help\n\n";print "This program prints out documents on a remote web server.\n";print "By default, the response code, header, and data are printed\n";print "but can be selectively printed with the -r, -H, and -d options.\n\n";usage();}# Given a URL, print out the data theresub hcat {# grab paramatersmy ($full_url, $response, $header, $data)=@_;# assume that response, header, and data will be printedmy $all = !($response || $header || $data);# if the URL isn't a full URL, assume that it is a http request$full_url="http://$full_url" if ($full_url !~m/(\w+):\/\/([^\/:]+)(:\d*)?([^#]*)/);# break up URL into meaningful partsmy @the_url = parse_URL($full_url);if (!defined @the_url) {print "Please use fully qualified valid URL\n";exit(-1);}# we're only interested in HTTP URL'sreturn if ($the_url[0] !~ m/http/i);# connect to server specified in 1st parameterif (!defined open_TCP('F', $the_url[1], $the_url[2])) {print "Error connecting to web server: $the_url[1]\n";exit(-1);}# request the path of the document to getprint F "GET $the_url[3] HTTP/1.0\n";print F "Accept: */*\n";print F "User-Agent: hcat/1.0\n\n";# print out server's response.# get the HTTP response linemy $the_response=<F>;print $the_response if ($all || defined $response);# get the header datawhile(<F>=~ m/^(\S+):\s+(.+)/) {print "$1: $2\n" if ($all || defined $header);}# get the entity bodyif ($all || defined $data) {print while (<F>);}# close the network connectionclose(F);}Shell Hypertext cat
With hcat, one can easily retrieve documents from remote web servers. But there are times when a client request needs to be more complex than hcat is willing to allow. To give the user more flexibility in sending client requests, we'll change hcat into shcat, a shell utility that accepts methods, headers, and entity-body data from standard input. With this program, you can write shell scripts that specify different methods, custom headers, and submit form data.
All of this can be done by changing a few lines around. In hcat, where you see this:
# request the path of the document to getprint F "GET $the_url[3] HTTP/1.0\n";print F "Accept: */*\n";print F "User-Agent: hcat/1.0\n\n";Replace it with this:
# copy STDIN to network connectionwhile (<STDIN>) {print F;}and save it as shcat. Now you can say whatever you want on shcat's STDIN, and it will forward it on to the web server you specify. This allows you to do things like HTML form postings with POST, or a file upload with PUT, and selectively look at the results. At this point, it's really all up to you what you want to say, as long as it's HTTP compliant.
Here's a UNIX shell script example that calls shcat to do a file upload:
#!/bin/kshecho "PUT /~apm/hi.txt HTTP/1.0User-Agent: shcat/1.0Accept: */*Content-type: text/plainContent-length: 2hi" | shcat http://publish.ora.com/Grep out URL References
When you need to quickly get a list of all the references in an HTML page, here's a utility you can use to fetch an HTML page from a server and print out the URLs referenced within the page. We've taken the hcat code and modified it a little. There's also another function that we added to parse out URLs from the HTML. Let's go over that first:
sub grab_urls {my($data, %tags) = @_;my @urls;# while there are HTML tagsskip_others: while ($data =~ s/<([^>]*)>//) {my $in_brackets=$1;my $key;foreach $key (keys %tags) {if ($in_brackets =~ /^\s*$key\s+/i) { # if tag matches, try parmsif ($in_brackets =~ /\s+$tags{$key}\s*=\s*"([^"]*)"/i) {my $link=$1;$link =~ s/[\n\r]//g; # kill newlines,returns anywhere in urlpush (@urls, $link);next skip_others;}# handle case when url isn't in quotes (ie: <a href=thing>)elsif ($in_brackets =~ /\s+$tags{$key}\s*=\s*([^\s]+)/i) {my $link=$1;$link =~ s/[\n\r]//g; # kill newlines,returns anywhere in urlpush (@urls, $link);next skip_others;}} # if tag matches} # foreach tag} # while there are brackets@urls;}The grab_urls( ) function has two parameters. The first argument is a scalar containing the HTML data to go through. The second argument is a hash of tags and parameters that we're looking for. After going through the HTML, grab_urls( ) returns an array of links that matched the regular expression of the form: <tag parameter="...">. The outer if statement looks for HTML tags, like <A>, <IMG>, <BODY>, <FRAME>. The inner if statement looks for parameters to the tags, like SRC and HREF, followed by text. Upon finding a match, the referenced URL is pushed into an array, which is returned at the end of the function. We've saved this in web.pl, and will include it in the hgrepurl program with a require 'web.pl'.
The second major change from hcat to hgrepurl is the addition of:
my $data='';# get the entity bodywhile (<F>) {$data.=$_};# close the network connectionclose(F);# fetch images and hyperlinks into arrays, print them outif (defined $images || $all) {@links=grab_urls($data, ('img', 'src', 'body', 'background'));}if (defined $hyperlinks || $all) {@links2= grab_urls($data, ('a', 'href'));}my $link;for $link (@links, @links2) { print "$link\n"; }This appends the entity-body into the scalar of $data. From there, we call grab_urls( ) twice. The first time looks for image references by recognizing <img src="..."> and <body background="..."> in the HTML. The second time looks for hyperlinks by searching for instances of <a href="...">. Each call to grab_urls( ) returns an array of URLs, stored in @links and @links2, respectively. Finally, we print the results out.
Other than that, there are some smaller changes. For example, we look at the response code. If it isn't 200 (OK), we skip it.
# if not an "OK" response of 200, skip itif ($the_response !~ m@^HTTP/\d+\.\d+\s+200\s@) {return;}We've retrofitted the reading of the response line, headers, and entity-body to not echo to STDOUT. This isn't needed anymore in the context of this program. Also, instead of parsing the -r, -H, and -d command-line arguments, we look for -i for displaying image links only, and -l for displaying only hyperlinks.
So, to see just the image references at www.ora.com, one would do this:
% hgrepurl -i http://www.ora.comOr just the hyperlinks at www.ora.com:
% hgrepurl -l http://www.ora.comOr both images and hyperlinks at www.ora.com:
% hgrepurl http://www.ora.comThe complete source code looks like this:
#!/usr/local/bin/perl -w# socket based hypertext grep URLs. Given a URL, this# prints out URLs of hyperlinks and images.use strict;use Socket; # include Socket modulerequire 'tcp.pl'; # file with Open_TCP routinerequire 'web.pl'; # file with parseURL routineuse vars qw($opt_h $opt_i $opt_l);use Getopt::Std;# parse command line argumentsgetopts('hil');# print out usage if neededif (defined $opt_h || $#ARGV<0) { help(); }# if it wasn't an option, it was a URLwhile($_ = shift @ARGV) {hgu($_, $opt_i, $opt_l);}# Subroutine to print out usage informationsub usage {print "usage: $0 -hil URL(s)\n";print " -h help\n";print " -i print out image URLs\n";print " -l print out hyperlink URLs\n";exit(-1);}# Subroutine to print out help text along with usage informationsub help {print "Hypertext grep URL help\n\n";print "This program prints out hyperlink and image links that\n";print "are referenced by a user supplied URL on a web server.\n\n";usage();}# hypertext grep urlsub hgu {# grab parametersmy($full_url, $images, $hyperlinks)=@_;my $all = !($images || $hyperlinks);my @links;my @links2;# if the URL isn't a full URL, assume that it is a http request$full_url="http://$full_url" if ($full_url !~m/(\w+):\/\/([^\/:]+)(:\d*)?([^#]*)/);# break up URL into meaningful partsmy @the_url = parse_URL($full_url);if (!defined @the_url) {print "Please use fully qualified valid URL\n";exit(-1);}# we're only interested in HTTP URL'sreturn if ($the_url[0] !~ m/http/i);# connect to server specified in 1st parameterif (!defined open_TCP('F', $the_url[1], $the_url[2])) {print "Error connecting to web server: $the_url[1]\n";exit(-1);}# request the path of the document to getprint F "GET $the_url[3] HTTP/1.0\n";print F "Accept: */*\n";print F "User-Agent: hgrepurl/1.0\n\n";# print out server's response.# get the HTTP response linemy $the_response=<F>;# if not an "OK" response of 200, skip itif ($the_response !~ m@^HTTP/\d+\.\d+\s+200\s@) {return;}# get the header datawhile(<F>=~ m/^(\S+):\s+(.+)/) {# skip over the headers}my $data='';# get the entity bodywhile (<F>) {$data.=$_};# close the network connectionclose(F);# fetch images and hyperlinks into arrays, print them outif (defined $images || $all) {@links=grab_urls($data, ('img', 'src', 'body', 'background'));}if (defined $hyperlinks || $all) {@links2= grab_urls($data, ('a', 'href'));}my $link;for $link (@links, @links2) { print "$link\n"; }}Client Design Considerations
Now that we've done a few examples, let's address some issues that arise when developing, testing, and using web client software. Most of these issues are automatically handled by LWP, but when programming directly with sockets, you have to take care of them yourself.
- How does your client handle tag parameters?
- The decision to process or ignore extra tag parameters depends on the application of the web client. Some tag parameters change the tag's appearance by adjusting colors or sizes. Other tags are informational, like variable names and hidden variable declarations in HTML forms. Your client may need to pay close attention to these tags. For example, if your client sends form data, it may want to check all the parameters. Otherwise, your client may send data that is inconsistent with what the HTML specified--e.g., an HTML form might specify that a variable's value may not exceed a length of 20 characters. If the client ignored this parameter, it might send data over 20 characters. As the HTML standard evolves, your client may require some updating.
- What does your client do when the server's expected HTML format changes?
- Examine the data coming back from the server. After your client can handle the current data, think about possible changes that may occur in the data. Some changes won't affect your client's functionality. For example, textual descriptions in a file listing may be updated. But other changes, like the general format of the HTML, may cause your current client to interpret important values incorrectly. Changes in data may be unpredictable. When your client doesn't understand the data, it is safer for the client not to assume anything, to abort its current operation, and to notify someone to look into it. The client may need to be updated to handle the changes at the server.
- Does the client analyze the response line and headers?
- It is not advisable to write clients that skip over the HTTP response line and headers. While it may be easier to do so, it often comes back to haunt you later. For example, if the URL used by the client becomes obsolete or is changed, the client may interpret the entity-body incorrectly. Media types for the URL may change, and could be noticed in the HTTP headers returned by the server. In general, the client should be equipped to handle variations in metadata as they occur.
- Does your client handle URL redirection? Does it need to?
- Perhaps the desired data still exists, but not at the location specified by your client. In the event of a redirection, will your client handle it? Does it examine the Location header? The answers to these questions depend on the purpose of the client.
- Does the client send authorization information when it shouldn't?
- Two or more separate organizations may have CGI programs on the same server. It is important for your client not to send authorization information unless it is requested. Otherwise, the client may expose its authentication to an outside organization. This opens up the user's account to outsiders.
- What does your client do when the server is down?
- When the server is down, there are several options. The most obvious option is for the client to attempt the HTTP request at a later time. Other options are to try an alternate server or abort the transaction. The programmer should give the user some configuration options about the client's actions.
- What does your client do when the server response time is long?
- For simple applications, it may be better to allow the user to interrupt the application. For user-friendly or unattended batch applications, it is desirable to time out the connection and notify the user.
- What does your client do when the server has a higher version of HTTP?
- And what happens when the client doesn't understand the response? The most logical thing is to attempt to talk on a common denominator. Chances are that just about anything will understand HTTP/1.0, if that's what you feel comfortable using. In most cases, if the client doesn't understand the response, it would be nice to tell the user--or at least let the user know to get the latest version of HTTP for the client!
Back to: Chapter Index
Back to: Web Client Programming with Perl
© 2001, O'Reilly & Associates, Inc.
[email protected]