
Web Client Programming with Perl
Automating Tasks on the Web
By Clinton Wong1st Edition March 1997
This book is out of print, but it has been made available online through the O'Reilly Open Books Project.
|
|
|
|
|
Web Client Programming with PerlAutomating Tasks on the WebBy Clinton Wong1st Edition March 1997 This book is out of print, but it has been made available online through the O'Reilly Open Books Project. |
Chapter 5.
The LWP Library
In this chapter:
Some Simple Examples
Listing of LWP Modules
Using LWP
As we showed in Chapter 1, the Web works over TCP/IP, in which the client and server establish a connection and then exchange necessary information over that connection. Chapters See Demystifying the Browser and See Learning HTTP concentrated on HTTP, the protocol spoken between web clients and servers. Now we'll fill in the rest of the puzzle: how your program establishes and manages the connection required for speaking HTTP.
In writing web clients and servers in Perl, there are two approaches. You can establish a connection manually using sockets, and then use raw HTTP; or you can use the library modules for WWW access in Perl, otherwise known as LWP. LWP is a set of modules for Perl 5 that encapsulate common functions for a web client or server. Since LWP is much faster and cleaner than using sockets, this book uses it for all the examples in Chapters See Example LWP Programs and . If LWP is not available on your platform, see Chapter 4, which gives more detailed descriptions of the socket calls and examples of simple web programs using sockets.
The LWP library is available at all CPAN archives. CPAN is a collection of Perl libraries and utilities, freely available to all. There are many CPAN mirror sites; you should use the one closest to you, or just go to http://www.perl.com/CPAN/ to have one chosen for you at random. LWP was developed by a cast of thousands (well, maybe a dozen), but its primary driving force is Gisle Aas. It is based on the libwww library developed for Perl 4 by Roy Fielding.
Detailed discussion of each of the routines within LWP is beyond the scope of this book. However, we'll show you how LWP can be used, and give you a taste of it to get you started. This chapter is divided into three sections:
- First, we'll show you some very simple LWP examples, to give you an idea of what it makes possible.
- Next, we'll list most of the useful routines within the LWP library.
- At the end of the chapter, we'll present some examples that glue together the different components of LWP.
Some Simple Examples
LWP is distributed with a very helpful--but very short--"cookbook" tutorial, designed to get you started. This section serves much the same function: to show you some simpler applications using LWP.
Retrieving a File
In Chapter 4, we showed how a web client can be written by manually opening a socket to the server and using I/O routines to send a request and intercept the result. With LWP, however, you can bypass much of the dirty work. To give you an idea of how simple LWP can make things, here's a program that retrieves the URL in the command line and prints it to standard output:
#!/bin/perluse LWP::Simple;print (get $ARGV[0]);The first line, starting with #!, is the standard line that calls the Perl interpreter. If you want to try this example on your own system, it's likely you'll have to change this line to match the location of the Perl 5 interpreter on your system.
The second line, starting with use, declares that the program will use the LWP::Simple class. This class of routines defines the most basic HTTP commands, such as get.
The third line uses the get( ) routine from LWP::Simple on the first argument from the command line, and applies the result to the print( ) routine.
Can it get much easier than this? Actually, yes. There's also a getprint( ) routine in LWP::Simple for getting and printing a document in one fell swoop. The third line of the program could also read:
getprint($ARGV[0]);That's it. Obviously there's some error checking that you could do, but if you just want to get your feet wet with a simple web client, this example will do. You can call the program geturl and make it executable; for example, on UNIX:
% chmod +x geturlWindows NT users can use the pl2bat program, included with the Perl distribution, to make the geturl.pl executable from the command line:
C:\your\path\here> pl2bat geturlYou can then call the program to retrieve any URL from the Web:
% geturl http://www.ora.com/<HTML><HEAD><LINK REV=MADE HREF="mailto:[email protected]"><TITLE>O'Reilly & Associates</TITLE></HEAD><BODY bgcolor=#ffffff>...Parsing HTML
Since HTML is hard to read in text format, instead of printing the raw HTML, you could strip it of HTML codes for easier reading. You could try to do it manually:
#!/bin/perluse LWP::Simple;foreach (get $ARGV[0]) {s/<[^>]*>//g;print;}But this only does a little bit of the job. Why reinvent the wheel? There's something in the LWP library that does this for you. To parse the HTML, you can use the HTML module:
#!/bin/perluse LWP::Simple;use HTML::Parse;print parse_html(get ($ARGV[0]))->format;In addition to LWP::Simple, we include the HTML::Parse class. We call the parse_html( ) routine on the result of the get( ), and then format it for printing.
You can save this version of the program under the name showurl, make it executable, and see what happens:
% showurl http://www.ora.com/O'Reilly & AssociatesAbout O'Reilly -- Feedback -- Writing for O'ReillyWhat's New -- Here's a sampling of our most recent postings...* This Week in Web Review: Tracking AdsAre you running your Web site like a business? These tools can help.* Traveling with your dog? Enter the latest Travelers' Taleswriting contest and send us a tale.New and Upcoming Releases...Extracting Links
To find out which hyperlinks are referenced inside an HTML page, you could go to the trouble of writing a program to search for text within angle brackets (<...>), parse the enclosed text for the <A> or <IMG> tag, and extract the hyperlink that appears after the HREF or SRC parameter. LWP simplifies this process down to two function calls. Let's take the geturl program from before and modify it:
#!/usr/local/bin/perluse LWP::Simple;use HTML::Parse;use HTML::Element;$html = get $ARGV[0];$parsed_html = HTML::Parse::parse_html($html);for (@{ $parsed_html->extract_links( ) }) {$link = $_->[0];print "$link\n";}The first change to notice is that in addition to LWP::Simple and HTML::Parse, we added the HTML::Element class.
Then we get the document and pass it to HTML::Parse::parse_html( ). Given HTML data, the parse_html( ) function parses the document into an internal representation used by LWP.
$parsed_html = HTML::Parse::parse_html($html);Here, the parse_html( ) function returns an instance of the HTML::TreeBuilder class that contains the parsed HTML data. Since the HTML::TreeBuilder class inherits the HTML::Element class, we make use of HTML::Element::extract_links( ) to find all the hyperlinks mentioned in the HTML data:
for (@{ $parsed_html->extract_links( ) }) {extract_links( ) returns a list of array references, where each array in the list contains a hyperlink mentioned in the HTML. Before we can access the hyperlink returned by extract_links( ), we dereference the list in the for loop:
for (@{ $parsed_html->extract_links( ) }) {and dereference the array within the list with:
$link = $_->[0];After the deferencing, we have direct access to the hyperlink's location, and we print it out:
print "$link\n";Save this program into a file called showlink and run it:
% showlink http://www.ora.com/You'll see something like this:
graphics/texture.black.gif/maps/homepage.map/graphics/headers/homepage-anim.gifhttp://www.oreilly.de/o/comsec/satan/index.html/ads/international/satan.gifhttp://www.ora.com/catalog/pperl2...Expanding Relative URLs
From the previous example, the links from showlink printed out the hyperlinks exactly as they appear within the HTML. But in some cases, you want to see the link as an absolute URL, with the full glory of a URL's scheme, hostname, and path. Let's modify showlink to print out absolute URLs all the time:
#!/usr/local/bin/perluse LWP::Simple;use HTML::Parse;use HTML::Element;use URI::URL;$html = get $ARGV[0];$parsed_html = HTML::Parse::parse_html($html);for (@{ $parsed_html->extract_links( ) }) {$link=$_->[0];$url = new URI::URL $link;$full_url = $url->abs($ARGV[0]);print "$full_url\n";}In this example, we've added URI::URL to our ever-expanding list of classes. To expand each hyperlink, we first define each hyperlink in terms of the URL class:
$url = new URI::URL $link;Then we use a method in the URL class to expand the hyperlink's URL, with respect to the location of the page it was referenced from:
$full_url = $url->abs($ARGV[0]);Save the program in a file called fulllink, make it executable, and run it:
% fulllink http://www.ora.com/You should see something like this:
http://www.ora.com/graphics/texture.black.gifhttp://www.ora.com/maps/homepage.maphttp://www.ora.com/graphics/headers/homepage-anim.gifhttp://www.oreilly.de/o/comsec/satan/index.htmlhttp://www.ora.com/ads/international/satan.gifhttp://www.ora.com/catalog/pperl2...You should now have an idea of how easy LWP can be. There are more examples at the end of this chapter, and the examples in Chapters See Example LWP Programs and all use LWP. Right now, let's talk a little more about the more interesting modules, so you know what's possible under LWP and how everything ties together.
Listing of LWP Modules
There are eight main modules in LWP: File, Font, HTML, HTTP, LWP, MIME, URI, and WWW. Figure 5-1 sketches out the top-level hierarchy within LWP.
Figure 5-1. The top-level LWP hierarchy
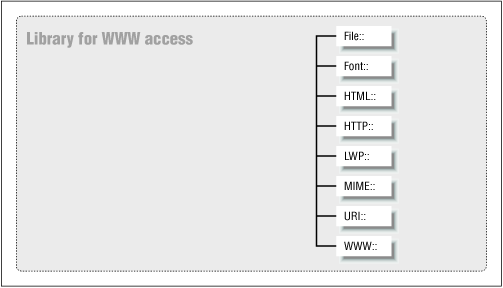
- The File module parses directory listings.
- The Font module handles Adobe Font Metrics.
- In the HTML module, HTML syntax trees can be constructed in a variety of ways. These trees are used in rendering functions that translate HTML to PostScript or plain text.
- The HTTP module describes client requests, server responses, and dates, and computes a client/server negotiation.
- The LWP module is the core of all web client programs. It allows the client to communicate over the network with the server.
- The MIME module converts to/from base 64 and quoted printable text.
- In the URI module, one can escape a URI or specify or translate relative URLs to absolute URLs.
- Finally, in the WWW module, the client can determine if a server's resource is accessible via the Robot Exclusion Standard.
In the context of web clients, some modules in LWP are more useful than others. In this book, we cover LWP, HTML, HTTP, and URI. HTTP describes what we're looking for, LWP requests what we're looking for, and the HTML module is useful for interpreting HTML and converting it to some other form, such as PostScript or plain text. The URI module is useful for dissecting fully constructed URLs, specifying a URL for the HTTP or LWP module, or performing operations on URLs, such as escaping or expanding.
In this section, we'll give you an overview of the some of the more useful functions and methods in the LWP, HTML, HTTP, and URI modules. The other methods, functions, and modules are, as the phrase goes, beyond the scope of this book. So, let's go over the core modules that are useful for client programming.
The LWP Module
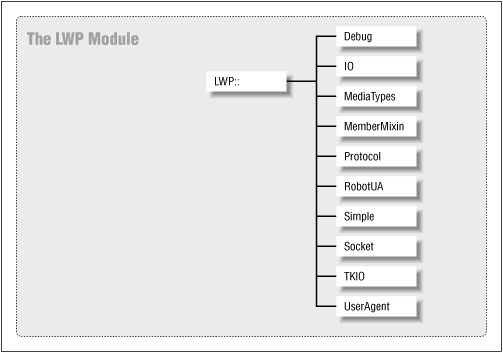
The LWP module, in the context of web clients, performs client requests over the network. There are 10 classes in all within the LWP module, as shown in Figure 5-2, but we're mainly interested in the Simple, UserAgent, and RobotUA classes, described below.
Figure 5-2. LWP classes
LWP::Simple
When you want to quickly design a web client, but robustness and complex behavior are of secondary importance, the LWP::Simple class comes in handy. Within it, there are seven functions:
- get($url)
- Returns the contents of the URL specified by $url. Upon failure, get( ) returns undef. Other than returning undef, there is no way of accessing the HTTP status code or headers returned by the server.
- head($url)
- Returns header information about the URL specified by $url in the form of: ($content_type, $document_length, $modified_time, $expires, $server). Upon failure, head( ) returns an empty list.
- getprint($url)
- Prints the contents of the URL on standard output, where the URL is specified by $url. The HTTP status code given by the server is returned by getprint( ).
- getstore($url, $file)
- Stores the contents of the URL specified by $url into a file named by $file. The HTTP status code is returned by getstore( ).
- mirror($url, $file)
- Copies the contents of the URL specified by $url into a file named by $file, when the modification time or length of the online version is different from that of the file.
- is_success($rc)
- Given a status code from getprint( ), getstore( ), or mirror( ), returns true if the request was successful.
- is_error($rc)
- Given a status code from getprint( ), getstore( ), or mirror( ), returns true if the request was not successful.
LWP::UserAgent
Requests over the network are performed with the LWP::UserAgent module. To create an LWP::UserAgent object, you would do:
$ua = new LWP::UserAgent;The most useful method in this module is request( ), which contacts a server and returns the result of your query. Other methods in this module change the way request( ) behaves. You can change the timeout value, customize the value of the User-Agent header, or use a proxy server. Here's an overview of most of the useful methods:
- $ua->request($request [, $subroutine [, $size]])
- Performs a request for the resource specified by $request, which is an HTTP::Request object. Normally, doing a $result=$ua->request($request) is enough. On the other hand, if you want to request data as it becomes available, you can specify a reference to a subroutine as the second argument, and request( ) will call the subroutine whenever there are data to be processed. In that case, you can specify an optional third argument that specifies the desired size of the data to be processed. The subroutine should expect chunks of the entity-body data as a scalar as the first parameter, a reference to an HTTP::Response object as the second argument, and a reference to an LWP::Protocol object as the third argument.
- $ua->request($request, $file_path)
- When invoked with a file path as the second parameter, this method writes the entity-body of the response to the file, instead of the HTTP::Response object that is returned. However, the HTTP::Response object can still be queried for its response code.
- $ua->credentials($netloc, $realm, $uname, $pass)
- Use the supplied username and password for the given network location and realm. To use the username "webmaster" and password of "yourguess" with the "admin" realm at www.ora.com, you would do this:
$ua->credentials('www.ora.com', 'admin', 'webmaster', 'yourguess').- $ua->get_basic_credentials($realm, $url)
- Returns ($uname, $pass) for the given realm and URL. get_basic_credentials( ) is usually called by request( ). This method becomes useful when creating a subclass of LWP::UserAgent with its own version of get_basic_credentials( ). From there, you can rewrite get_basic_credentials( ) to do more flexible things, like asking the user for the account information, or referring to authentication information in a file, or whatever. All you need to do is return a list, where the first element is a username and the second element is a password.
- $ua->agent([$product_id])
- When invoked with no arguments, this method returns the current value of the identifier used in the User-Agent HTTP header. If invoked with an argument, the User-Agent header will use that identifier in the future. (As described in Chapter 3, the User-Agent header tells a web server what kind of client software is performing the request.)
- $ua->from([$email_address])
- When invoked with no arguments, this method returns the current value of the email address used in the From HTTP header. If invoked with an argument, the From header will use that email address in the future. (The From header tells the web server the email address of the person running the client software.)
- $ua->timeout([$secs])
- When invoked with no arguments, the timeout( ) method returns the timeout value of a request. By default, this value is three minutes. So if the client software doesn't hear back from the server within three minutes, it will stop the transaction and indicate that a timeout occurred in the HTTP response code. If invoked with an argument, the timeout value is redefined to be that value.
- $ua->use_alarm([$boolean])
- Retrieves or defines the ability to use alarm( ) for timeouts. By default, timeouts with alarm( ) are enabled. If you plan on using alarm( ) for your own purposes, or alarm( ) isn't supported on your system, it is recommended that you disable alarm( ) by calling this method with a value of 0 (zero).
- $ua->is_protocol_supported($scheme)
- Given a scheme, this method returns a true or false (nonzero or zero) value. A true value means that LWP knows how to handle a URL with the specified scheme. If it returns a false value, LWP does not know how to handle the URL.
- $ua->mirror($url, $file)
- Given a URL and file path, this method copies the contents of $url into the file when the length or modification date headers are different. If the file does not exist, it is created. This method returns an HTTP::Response object, where the response code indicates what happened.
- $ua->proxy( (@scheme | $scheme), $proxy_url)
- Defines a URL to use with the specified schemes. The first parameter can be an array of scheme names or a scalar that defines a single scheme. The second argument defines the proxy's URL to use with the scheme.
- $ua->env_proxy( )
- Defines a scheme/proxy URL mapping by looking at environment variables. For example, to define the HTTP proxy, one would define the http_proxy environment variable with the proxy's URL. To define a domain to avoid the proxy, one would define the no_proxy environment variable with the domain that doesn't need a proxy.
- $ua->no_proxy($domain,...)
- Do not use a proxy server for the domains given as parameters.
LWP::RobotUA
The Robot User Agent (LWP::RobotUA) is a subclass of LWP::UserAgent. User agent applications directly reflect the actions of the user. For example, in a user agent application, when a user clicks on a hyperlink, he expects to see the data associated with the hyperlink. On the other hand, a robot application requests resources in an automated fashion. Robot applications cover such activities as searching, mirroring, and surveying. Some robots collect statistics, while others wander the Web and summarize their findings for a search engine. For this type of application, a robot application should use LWP::RobotUA instead of LWP::UserAgent. The LWP::RobotUA module observes the Robot Exclusion Standards, which web server administrators can define on their web site to keep robots away from certain (or all) areas of the web site.[1] To create a new LWP::RobotUA object, one could do:
$ua = LWP::RobotUA->new($agent_name, $from, [$rules])where the first parameter is the identifier that defines the value of the User-Agent header in the request, the second parameter is the email address of the person using the robot, and the optional third parameter is a reference to a WWW::RobotRules object. If you omit the third parameter, the LWP::RobotUA module requests the robots.txt file from every server it contacts, and generates its own WWW::RobotRules object.
Since LWP::RobotUA is a subclass of LWP::UserAgent, the LWP::UserAgent methods are also available in LWP::RobotUA. In addition, LWP::RobotUA has the following robot-related methods:
- $ua->delay([$minutes])
- Returns the number of minutes to wait between requests. If a parameter is given, the time to wait is redefined to be the time given by the parameter. Upon default, this value is 1 (one). It is generally not very nice to set a time of zero.
- $ua->rules([$rules])
- Returns or defines a the WWW:RobotRules object to be used when determining if the module is allowed access to a particular resource.
- $ua->no_visits($netloc)
- Returns the number of visits to a given server. $netloc is of the form: user:password@host:port. The user, password, and port are optional.
- $ua->host_wait($netloc)
- Returns the number of seconds the robot must wait before it can request another resource from the server. $netloc is of the form of: user:password@host:port. The user, password, and port are optional.
- $ua->as_string( )
- Returns a human-readable string that describes the robot's status.
The HTTP Module
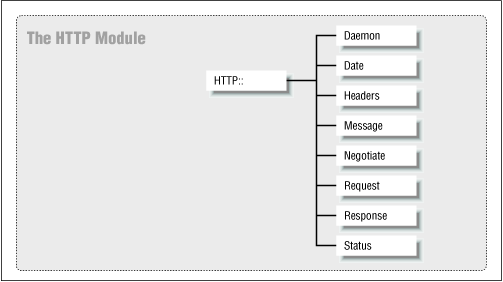
The HTTP module specifies HTTP requests and responses, plus some helper functions to interpret or convert data related to HTTP requests and responses. There are eight classes within the HTTP module, as shown in Figure 5-3, but we're mainly interested in the Request, Response, Header, and Status classes.
Figure 5-3. Structure of the HTTP module
The two main modules that you'll use in the HTTP module are HTTP::Request and HTTP::Response. HTTP::Request allows one to specify a request method, URL, headers, and entity-body. HTTP::Response specifies a HTTP response code, headers, and entity-body. Both HTTP::Request and HTTP::Response are subclasses of HTTP::Message and inherit HTTP::Message's facility to handle headers and an entity-body.
For both HTTP::Request and HTTP::Response, you might want to define the headers in your request or look at the headers in the response. In this case, you can use HTTP::Headers to poke around with your HTTP::Request or HTTP::Response object.
In addition to HTTP::Headers for looking at HTTP::Response headers, HTTP::Status includes functions to classify response codes into the categories of informational, successful, redirection, error, client error, or server error. It also exports symbolic aliases of HTTP response codes; one could refer to the status code of 200 as RC_OK, and refer to 404 as RC_NOT_FOUND.
The HTTP::Date module converts date strings from and to machine time.
HTTP::Request
This module summarizes a web client's request. For a simple GET or HEAD request, you could define the GET method and a URL to apply it to, and the headers would be filled in by LWP. For a POST or PUT, you might want to specify a custom HTTP::Headers object at the third parameter, or the $content parameter for an entity-body. Since HTTP::Request inherits everything in HTTP::Message, you can use the header and entity-body manipulation methods from HTTP::Message in HTTP::Request objects.
- $r = new HTTP::Request $method, $url, [$header, [$content]]
- The first parameter, $method, expects an HTTP method, like GET, HEAD, POST, PUT, etc. The second parameter, $url, is the URL to apply the method to. This can be a string, like "www.ora.com", or a reference to a URI::URL object. To specify your own headers, you can specify an optional third parameter as a reference to an HTTP::Headers object. The fourth parameter, also optional, is a scalar that specifies the HTTP entity-body of the request. If omitted, the entity-body is empty.
- $r->method([$val])
- To see what the HTTP::Request object has as its HTTP method, call the object's method( ) method without any parameters, and it will return the object's current HTTP method. To define a new HTTP method for the HTTP::Request object, call the object's method( ) method with your new HTTP method.[2]
- $r->url([$val])
- To see what the HTTP::Request object has as its request URL, call the object's url( ) method without any parameters, and it will return the object's current URL. To define a new URL, call url( ) with your new URL as a parameter, like $myobject->url('www.ora.com').
- $r->header($field [=> $val],...)
- When called with just an HTTP header as a parameter, this method returns the current value for the header. For example, $myobject->('content-type') would return the value for the object's Content-type header. To define a new header value, invoke header( ) with an associative array with header => value pairs, where the value is a scalar or reference to an array. For example, to define the Content-type header, you would do this:
$r->header('Content-type' => 'text/plain')- By the way, since HTTP::Request inherits HTTP::Message, and HTTP::Message contains all the methods of HTTP::Headers, you can use all the HTTP::Headers methods within an HTTP::Request object. See "HTTP::Headers" later in this section.
- $r->content([$content])
- To get the entity-body of the request, call the content( ) method without any parameters, and it will return the object's current entity-body. To define the entity-body, invoke content( ) with a scalar as its first parameter. This method, by the way, is inherited from HTTP::Message.
- $r->add_content($data)
- Appends $data to the end of the object's current entity-body.
- $r->as_string( )
- This returns a text version of the request, useful for debugging purposes. For example:
use HTTP::Request;$request = new HTTP::Request 'PUT', 'http://www.ora.com/example/hi.text';$request->header('content-length' => 2);$request->header('content-type' => 'text/plain');$request->content('hi');print $request->as_string( );would look like this:
--- HTTP::Request=HASH(0x68148) ---PUT http://www.ora.com/example/hi.textContent-Length: 2Content-Type: text/plainhi-----------------------------------HTTP::Response
Responses from a web server are described by HTTP::Response objects. If LWP has problems fulfilling your request, it internally generates an HTTP::Response object and fills in an appropriate response code. In the context of web client programming, you'll usually get an HTTP::Response object from LWP::UserAgent and LWP::RobotUA. If you plan to write extensions to LWP or a web server or proxy server, you might use HTTP::Response to generate your own responses.
- $r = new HTTP::Response ($rc, [$msg, [$header, [$content]]])
- In its simplest form, an HTTP::Response object can contain just a response code. If you would like to specify a more detailed message than "OK" or "Not found," you can specify a human-readable description of the response code as the second parameter. As a third parameter, you can pass a reference to an HTTP::Headers object to specify the response headers. Finally, you can also include an entity-body in the fourth parameter as a scalar.
- $r->code([$code])
- When invoked without any parameters, the code( ) method returns the object's response code. When invoked with a status code as the first parameter, code( ) defines the object's response to that value.
- $r->is_info( )
- Returns true when the response code is 100 through 199.
- $r->is_success( )
- Returns true when the response code is 200 through 299.
- $r->is_redirect( )
- Returns true when the response code is 300 through 399.
- $r->is_error( )
- Returns true when the response code is 400 through 599. When an error occurs, you might want to use error_as_HTML( ) to generate an HTML explanation of the error.
- $r->message([$message])
- Not to be confused with the entity-body of the response. This is the human-readable text that a user would usually see in the first line of an HTTP response from a server. With a response code of 200 (RC_OK), a common response would be a message of "OK" or "Document follows." When invoked without any parameters, the message( ) method returns the object's HTTP message. When invoked with a scalar parameter as the first parameter, message( ) defines the object's message to the scalar value.
- $r->header($field [=> $val],...)
- When called with just an HTTP header as a parameter, this method returns the current value for the header. For example, $myobject->('content-type') would return the value for the object's Content-type header. To define a new header value, invoke header( ) with an associative array of header => value pairs, where value is a scalar or reference to an array. For example, to define the Content-type header, one would do this:
$r->header('content-type' => 'text/plain')- By the way, since HTTP::Response inherits HTTP::Message, and HTTP::Message contains all the methods of HTTP::Headers, you can use all the HTTP::Headers methods within an HTTP::Response object. See "HTTP::Headers" later in this section.
- $r->content([$content])
- To get the entity-body of the request, call the content( ) method without any parameters, and it will return the object's current entity-body. To define the entity-body, invoke content( ) with a scalar as its first parameter. This method, by the way, is inherited from HTTP::Message.
- $r->add_content($data)
- Appends $data to the end of the object's current entity-body.
- $r->error_as_HTML( )
- When is_error( ) is true, this method returns an HTML explanation of what happened. LWP usually returns a plain text explanation.
- $r->base( )
- Returns the base of the request. If the response was hypertext, any links from the hypertext should be relative to the location specified by this method. LWP looks for the BASE tag in HTML and Content-base/Content-location HTTP headers for a base specification. If a base was not explicitly defined by the server, LWP uses the requesting URL as the base.
- $r->as_string( )
- This returns a text version of the response. Useful for debugging purposes. For example,
use HTTP::Response;use HTTP::Status;$response = new HTTP::Response(RC_OK, 'all is fine');$response->header('content-length' => 2);$response->header('content-type' => 'text/plain');$response->content('hi');print $response->as_string( );would look like this:
--- HTTP::Response=HASH(0xc8548) ---RC: 200 (OK)Message: all is fineContent-Length: 2Content-Type: text/plainhi------------------------------------ $r->current_age
- Returns the numbers of seconds since the response was generated by the original server. This is the current_age value as described in section 13.2.3 of the HTTP 1.1 spec 07 draft.
- $r->freshness_lifetime
- Returns the number of seconds until the response expires. If expiration was not specified by the server, LWP will make an informed guess based on the Last-modified header of the response.
- $r->is_fresh
- Returns true if the response has not yet expired. Returns true when (freshness_lifetime > current_age).
- $r->fresh_until
- Returns the time when the response expires. The time is based on the number of seconds since January 1, 1970, UTC.
HTTP::Headers
This module deals with HTTP header definition and manipulation. You can use these methods within HTTP::Request and HTTP::Response.
- $h = new HTTP::Headers([$field => $val],...)
- Defines a new HTTP::Headers object. You can pass in an optional associative array of header => value pairs.
- $h->header($field [=> $val],...)
- When called with just an HTTP header as a parameter, this method returns the current value for the header. For example, $myobject->('content-type') would return the value for the object's Content-type header. To define a new header value, invoke header( ) with an associative array of header => value pairs, where the value is a scalar or reference to an array. For example, to define the Content-type header, one would do this:
$h->header('content-type' => 'text/plain')- $h->push_header($field, $val)
- Appends the second parameter to the header specified by the first parameter. A subsequent call to header( ) would return an array. For example:
$h->push_header(Accept => 'image/jpeg');- $h->remove_header($field,...)
- Removes the header specified in the parameter(s) and the header's associated value.
HTTP::Status
This module provides functions to determine the type of a response code. It also exports a list of mnemonics that can be used by the programmer to refer to a status code.
- is_info( )
- Returns true when the response code is 100 through 199.
- is_success( )
- Returns true when the response code is 200 through 299.
- is_redirect( )
- Returns true when the response code is 300 through 399.
- is_client_error( )
- Returns true when the response code is 400 through 499.
- is_server_error( )
- Returns true when the response code is 500 through 599.
- is_error( )
- Returns true when the response code is 400 through 599. When an error occurs, you might want to use error_as_HTML( ) to generate an HTML explanation of the error.
There are some mnemonics exported by this module. You can use them in your programs. For example, you could do something like:
if ($rc = RC_OK) {....}Here are the mnemonics:
RC_CONTINUE (100)
RC_NOT_FOUND (404)
RC_SWITCHING_PROTOCOLS (101)
RC_METHOD_NOT_ALLOWED (405)
RC_OK (200)
RC_NOT_ACCEPTABLE (406)
RC_CREATED (201)
RC_PROXY_AUTHENTICATION_REQUIRED (407)
RC_ACCEPTED (202)
RC_REQUEST_TIMEOUT (408)
RC_NON_AUTHORITATIVE_INFORMATION (203)
RC_CONFLICT (409)
RC_NO_CONTENT (204)
RC_GONE (410)
RC_RESET_CONTENT (205)
RC_LENGTH_REQUIRED (411)
RC_PARTIAL_CONTENT (206)
RC_PRECONDITION_FAILED (412)
RC_MULTIPLE_CHOICES (300)
RC_REQUEST_ENTITY_TOO_LARGE (413)
RC_MOVED_PERMANENTLY (301)
RC_REQUEST_URI_TOO_LARGE (414)
RC_MOVED_TEMPORARILY (302)
RC_UNSUPPORTED_MEDIA_TYPE (415)
RC_SEE_OTHER (303)
RC_INTERNAL_SERVER_ERROR (500)
RC_NOT_MODIFIED (304)
RC_NOT_IMPLEMENTED (501)
RC_USE_PROXY (305)
RC_BAD_GATEWAY (502)
RC_BAD_REQUEST (400)
RC_SERVICE_UNAVAILABLE (503)
RC_UNAUTHORIZED (401)
RC_GATEWAY_TIMEOUT (504)
RC_PAYMENT_REQUIRED (402)
RC_HTTP_VERSION_NOT_SUPPORTED (505)
RC_FORBIDDEN (403)
See the section "Server Response Codes" in Chapter 3 for more information.
HTTP::Date
The HTTP::Date module is useful when you want to process a date string.
- time2str([$time])
- Given the number of seconds since machine epoch,[3] this function generates the equivalent time as specified in RFC 1123, which is the recommended time format used in HTTP. When invoked with no parameter, the current time is used.
- str2time($str [, $zone])
- Converts the time specified as a string in the first parameter into the number of seconds since epoch. This function recognizes a wide variety of formats, including RFC 1123 (standard HTTP), RFC 850, ANSI C asctime( ), common log file format, UNIX "ls -l", and Windows "dir", among others. When a time zone is not implicit in the first parameter, this function will use an optional time zone specified as the second parameter, such as "-0800" or "+0500" or "GMT". If the second parameter is omitted and the time zone is ambiguous, the local time zone is used.
The HTML Module
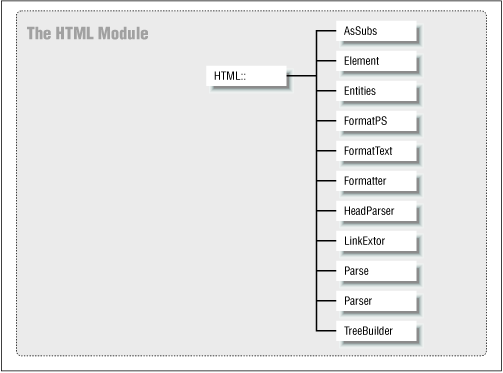
The HTML module provides an interface to parse HTML into an HTML parse tree, traverse the tree, and convert HTML to other formats. There are eleven classes in the HTML module, as shown in Figure 5-4.
Figure 5-4. Structure of the HTML module
Within the scope of this book, we're mostly interested in parsing the HTML into an HTML syntax tree, extracting links, and converting the HTML into text or PostScript. As a warning, chances are that you will need to explicitly do garbage collection when you're done with an HTML parse tree.[4]
HTML::Parse (superceded by HTML::Parser after LWP 5.2.2.)
- parse_html($html, [$obj])
- Given a scalar variable containing HTML as a first parameter, this function generates an HTML syntax tree and returns a reference to an object of type HTML::TreeBuilder. When invoked with an optional second parameter of type HTML::TreeBuilder,[5] the syntax tree is constructed with that object, instead of a new object. Since HTML::TreeBuilder inherits HTML::Parser and HTML::Element, methods from those classes can be used with the returned HTML::TreeBuilder object.
- parse_htmlfile($file, [$obj])
- Same as parse_html( ), except that the first parameter is a scalar containing the location of a file containing HTML.
With both parse_html( ) and parse_htmlfile( ), you can customize some of the parsing behavior with some flags:
- $HTML::Parse::IMPLICIT_TAGS
- Assumes certain elements and end tags when not explicitly mentioned in the HTML. This flag is on by default.
- $HTML::Parse::IGNORE_UNKNOWN
- Ignores unknown tags. On by default.
- $HTML::Parse::IGNORE_TEXT
- Ignores the text content of any element. Off by default.
- $HTML::Parse::WARN
- Calls warn( ) when there's a syntax error. Off by default.
HTML::Element
The HTML::Element module provides methods for dealing with nodes in an HTML syntax tree. You can get or set the contents of each node, traverse the tree, and delete a node. We'll cover delete( ) and extract_links( ).
- $h->delete( )
- Deallocates any memory used by this HTML element and any children of this element.
- $h->extract_links([@wantedTypes])
- Returns a list of hyperlinks as a reference to an array, where each element in the array is another array. The second array contains the hyperlink text and a reference to the HTML::Element that specifies the hyperlink. If invoked with no parameters, extract_links( ) will extract any hyperlink it can find. To specify certain types of hyperlinks, one can pass in an array of scalars, where the scalars are: body, base, a, img, form, input, link, frame, applet, and area.
- For example:
use HTML::Parse;$html='<img src="dot.gif"> <img src="dot2.gif">';$tree=HTML::Parse::parse_html($html);$link_ref = $tree->extract_links( );@link = @$link_ref; # dereference the array referencefor ($i=0; $i <= $#link; $i++) {print "$link[$i][0]\n";}- prints out:
dot.gifdot2.gifHTML::FormatText
The HTML::FormatText module converts an HTML parse tree into text.
- $formatter = new HTML::FormatText
- Creates a new HTML::FormatText object.
- $formatter->format($html)
- Given an HTML parse tree, as returned by HTML::Parse::parse_html( ), this method returns a text version of the HTML.
HTML::FormatPS
The HTML::FormatPS module converts an HTML parse tree into PostScript.
- $formatter = new HTML::FormatPS(parameter, ...)
- Creates a new HTML::FormatPS object with parameters of PostScript attributes. Each attribute is an associative array. One can define the following attributes:
- PaperSize
- Possible values of 3, A4, A5, B4, B5, Letter, Legal, Executive, Tabloid, Statement, Folio, 10x14, and Quarto. The default is A4.[6]
- PaperWidth
- Width of the paper in points.
- PaperHeight
- Height of the paper in points.
- LeftMargin
- Left margin in points.
- RightMargin
- Right margin in points.
- HorizontalMargin
- Left and right margin. Default is 4 cm.
- TopMargin
- Top margin in points.
- BottomMargin
- Bottom margin in points.
- VerticalMargin
- Top and bottom margin. Default is 2 cm.
- PageNo
- Boolean value to display page numbers. Default is 0 (off).
- FontFamily
- Font family to use on the page. Possible values are Courier, Helvetica and Times. Default is Times.
- FontScale
- Scale factor for the font.
- Leading
- Space between lines, as a factor of the font size. Default is 0.1.
- For example, you could do:
$formatter = new HTML::FormatPS('papersize' => 'Letter');- $formatter->format($html);
- Given an HTML syntax tree, returns the HTML representation as a scalar with PostScript content.
The URI Module
The URI module contains functions and modules to specify and convert URIs. (URLs are a type of URI.) There are only two classes within the URI module, as shown in Figure 5-5.
Figure 5-5. Structure of the URI module
We'll talk about escaping and unescaping URIs, as well as specifying URLs in the URI::URL module.
URI::Escape
- uri_escape($uri, [$escape])
- Given a URI as the first parameter, returns the equivalent URI with certain characters replaced with % followed by two hexadecimal digits. The first parameter can be a text string, like "http://www.ora.com", or an object of type URI::URL. When invoked without a second parameter, uri_escape( ) escapes characters specified by RFC 1738. Otherwise, one can pass in a regular expression (in the context of [ ]) of characters to escape as the second parameter. For example:
$escaped_uri = uri_escape($uri, 'aeiou')- escapes all lowercase vowels in $uri and returns the escaped version. You might wonder why one would want to escape certain characters in a URI. Here's an example: If a file on the server happens to contain a question mark, you would want to use this function to escape the question mark in the URI before sending the request to the server. Otherwise, the question mark would be interpreted by the server to be a query string separator.
- uri_unescape($uri)
- Substitutes any instance of % followed by two hexadecimal digits back into its original form and returns the entire URI in unescaped form.
URI::URL
- new URI::URL($url_string [, $base_url])
- Creates a new URI::URL object with the URL given as the first parameter. An optional base URL can be specified as the second parameter and is useful for generating an absolute URL from a relative URL.
- URI::URL::strict($bool)
- When set, the URI::URL module calls croak( ) upon encountering an error. When disabled, the URI::URL module may behave more gracefully. The function returns the previous value of strict( ).
- $url->base ([$base])
- Gets or sets the base URL associated with the URL in this URI::URL object. The base URL is useful for converting a relative URL into an absolute URL.
- $url->abs([$base, [$allow_scheme_in_relative_urls]])
- Returns the absolute URL, given a base. If invoked with no parameters, any previous definition of the base is used. The second parameter is a Boolean that modifies abs( )'s behavior. When the second parameter is nonzero, abs( ) will accept a relative URL with a scheme but no host, like "http:index.html". By default, this is off.
- $url->rel($base)
- Given a base as a first parameter or a previous definition of the base, returns the current object's URL relative to the base URL.
- $url->crack( )
- Returns an array with the following data:
- (scheme, user, password, host, port, epath, eparams, equery, frag)
- $url->scheme([$scheme])
- When invoked with no parameters, this returns the scheme in the URL defined in the object. When invoked with a parameter, the object's scheme is assigned to that value.
- $url->netloc( )
- When invoked with no parameters, this returns the network location for the URL defined in the object. The network location is a string composed of "user:password@host:port", where user, password, and port may be omitted when not defined. When netloc( ) is invoked with a parameter, the object's network location is defined to that value. Changes to the network location are reflected in the user( ), password( ), host( ), and port( ) method.
- $url->user( )
- When invoked with no parameters, this returns the user for the URL defined in the object. When invoked with a parameter, the object's user is assigned to that value.
- $url->password( )
- When invoked with no parameters, this returns the password in the URL defined in the object. When invoked with a parameter, the object's password is assigned to that value.
- $url->host( )
- When invoked with no parameters, this returns the hostname in the URL defined in the object. When invoked with a parameter, the object's hostname is assigned to that value.
- $url->port( )
- When invoked with no parameters, this returns the port for the URL defined in the object. If a port wasn't explicitly defined in the URL, a default port is assumed. When invoked with a parameter, the object's port is assigned to that value.
- $url->default_port( )
- When invoked with no parameters, this returns the default port for the URL defined in the object. The default port is based on the scheme used. Even if the port for the URL is explicitly changed by the user with the port( ) method, the default port is always the same.
- $url->epath( )
- When invoked with no parameters, this returns the escaped path of the URL defined in the object. When invoked with a parameter, the object's escaped path is assigned to that value.
- $url->path( )
- Same as epath( ) except that the path that is set/returned is not escaped.
- $url->eparams( )
- When invoked with no arguments, this returns the escaped parameter of the URL defined in the object. When invoked with an argument, the object's escaped parameter is assigned to that value.
- $url->params( )
- Same as eparams( ) except that the parameter that is set/returned is not escaped.
- $url->equery( )
- When invoked with no arguments, this returns the escaped query string of the URL defined in the object. When invoked with an argument, the object's escaped query string is assigned to that value.
- $url->query( )
- Same as equery( ) except that the parameter that is set/returned is not escaped.
- $url->frag( )
- When invoked with no arguments, this returns the fragment of the URL defined in the object. When invoked with an argument, the object's fragment is assigned to that value.
- $url->full_path( )
- Returns a string consisting of the escaped path, escaped parameters, and escaped query string.
- $url->eq($other_url)
- Returns true when the object's URL is equal to the URL specified by the first parameter.
- $url->as_string( )
- Returns the URL as a scalar string. All defined components of the URL are included in the string.
Using LWP
Let's try out some LWP examples and glue a few functions together to produce something useful. First, let's revisit a program from the beginning of the chapter:
#!/usr/local/bin/perluse LWP::Simple;print (get ($ARGV[0]));Because this is a short and simple example, there isn't a whole lot of flexibility here. For example, when LWP::Simple::get( ) fails, it doesn't give us a status code to use to figure out what went wrong. The program doesn't identify itself with the User-Agent header, and it doesn't support proxy servers. Let's change a few things.
Using LWP::UserAgent
LWP::UserAgent has its advantages when compared to LWP::Simple. With only a few more lines of code, one can follow HTTP redirections, authenticate requests, use the User-Agent and From headers, set a timeout, and use a proxy server. For the remainder of this chapter, we'll experiment with various aspects of LWP::UserAgent to show you how everything fits together.
First, let's convert our LWP::Simple program into something that uses LWP::UserAgent:
use LWP::UserAgent;use HTTP::Request;use HTTP::Response;my $ua = new LWP::UserAgent;my $request = new HTTP::Request('GET', $ARGV[0]);my $response = $ua->request($request);if ($response->is_success) {print $response->content;} else {print $response->error_as_HTML;}Save this program as hcat_plain. Now let's run it:
% hcat_plain http://www.ora.com/By converting to LWP::UserAgent, we've instantly gained the ability to report error messages and follow a URL redirection. Let's go through the code line by line, just to make sure you see how the different objects interact.
First, we include the modules that we plan to use in our program:
use LWP::UserAgent;use HTTP::Request;use HTTP::Response;Then we create a new LWP::UserAgent object:
my $ua = new LWP::UserAgent;We construct an HTTP request by creating a new HTTP::Request object. Within the constructor, we define the HTTP GET method and use the first argument ($ARGV[0] ) as the URL to get:
my $request = new HTTP::Request('GET', $ARGV[0]);We pass the HTTP::Request object to $ua's request( ) method. In other words, we're passing an HTTP::Request object to the LWP::UserAgent->request( ) method, where $ua is an instance of LWP::UserAgent. LWP::UserAgent performs the request and fetches the resource specified by $ARGV [0]. It returns a newly created HTTP::Response object, which we store in $response:
my $response = $ua->request($request);We examine the HTTP response code with HTTP::Response->is_success( ) by calling the is_success( ) method from the $response object. If the request was successful, we use HTTP::Response::content( ) by invoking $response's content( ) method to retrieve the entity-body of the response and print it out. Upon error, we use HTTP::Response::error_as_HTML by invoking $response's error_as_HTML( ) method to print out an error message as HTML.
In a nutshell, we create a request with an HTTP::Request object. We pass that request to LWP::UserAgent's request method, which does the actual request. It returns an HTTP::Response object, and we use methods in HTTP::Response to determine the response code and print out the results.
Adding Proxy Server Support
Let's add some more functionality to the previous example. In this case, we'll add support for a proxy server. A proxy server is usually used in firewall environments, where the HTTP request is sent to the proxy server, and the proxy server forwards the request to the real web server. If your network doesn't have a firewall, and you don't plan to have proxy support in your programs, then you can safely skip over this part now and come back when you eventually need it.
To show how flexible the LWP library is, we've added only two lines of code to the previous example, and now the web client knows that it should use the proxy at proxy.ora.com at port 8080 for HTTP requests, but to avoid using the proxy if the request is for a web server in the ora.com domain:
use LWP::UserAgent;use HTTP::Request;use HTTP::Response;my $ua = new LWP::UserAgent;$ua->proxy('http', 'http://proxy.ora.com:8080/');$ua->no_proxy('ora.com');my $request = new HTTP::Request('GET', $ARGV[0]);my $response = $ua->request($request);if ($response->is_success) {print $response->content;} else {print $response->error_as_HTML;}The invocation of this program is exactly the same as the previous example. If you downloaded this program from the O'Reilly web site, you could then use it like this:
% hcat_proxy http://www.ora.com/Adding Robot Exclusion Standard Support
Let's do one more example. This time, let's add support for the Robot Exclusion Standard. As discussed in the LWP::RobotUA section, the Robot Exclusion Standard gives webmasters the ability to block off certain areas of the web site from the automated "robot" type of web clients. It is arguable that the programs we've gone through so far aren't really robots; chances are that the user invoked the program by hand and is waiting for a reply. But for the sake of example, and to show how easy it is, let's add support for the Robot Exclusion Standard to our previous example.
use LWP::RobotUA;use HTTP::Request;use HTTP::Response;my $ua = new LWP::RobotUA('hcat_RobotUA', '[email protected]');$ua->proxy('http', 'http://proxy.ora.com:8080/');$ua->no_proxy('ora.com');my $request = new HTTP::Request('GET', $ARGV[0]);my $response = $ua->request($request);if ($response->is_success) {print $response->content;} else {print $response->error_as_HTML;}Since LWP::RobotUA is a subclass of LWP::UserAgent, LWP::RobotUA contains all the methods as LWP::UserAgent. So we replaced the use LWP::UserAgent line with use LWP::RobotUA. Instead of declaring a new LWP::UserAgent object, we declare a new LWP::RobotUA object.
LWP::RobotUA's constructor is a little different, though. Since we're programming a web robot, the name of the robot and the email address of the user are mandatory. So, we pass that information to the LWP::RobotUA object through the constructor. In practice, one would determine the email address of the client user in advance. The "[email protected]" is provided for illustration purposes only.
See Appendix C for more details about the Robot Exclusion Standard.
1. The Robot Exclusion Standard is currently available as an informational draft by Martijn Koster at http://info.webcrawler.com/mak/projects/robots/norobots-rfc.txt. Also see Appendix C for more information.
2. Where method( ) is in the object-oriented sense, like $myobject->method('GET'), and the other method is an HTTP method, like GET or HEAD.
3. Which is January 1, 1970, UTC on UNIX systems.
4. Since HTML syntax trees use circular references, the Perl garbage collector does not currently dispose of the memory used by the tree. You'll have to call the delete( ) method for the root node in an HTML syntax tree to manually deallocate memory used by the tree. Future versions of Perl or LWP may handle this automatically. See online documentation at www.perl.com for up-to-date information.
5. Or a subclass of HTML::Parser, which HTML::TreeBuilder happens to be.
6. A4 is the standard paper size in Europe. Americans will probably want to change this to Letter.
Back to: Chapter Index
Back to: Web Client Programming with Perl
© 2001, O'Reilly & Associates, Inc.
[email protected]