Chapter 3. The GNOME Build Environment
Part of writing a proper GNOME application is knowing how everything fits into the big picture. GNOME is not 100 percent GNOME code, but rather a rich strata, each layer depending on the layer beneath to support it.
GNOME uses the GNU build system, a powerful suite of tools created to ease the burden of compiling, porting, and installing free software. This build system employs macros and scripts to deal with the repetitive drudgery that software projects normally require. No longer will you have to spend hours and hours handcrafting build scripts and cutting and pasting makefile rules into new projects. The GNU build system can produce a complete, full-blooded compilation environment for your project with as little as three files and a dozen handwritten lines of text. All the reams of duplicated setup code are automatically generated by the GNU build tools. As a result, you can spend your valuable time writing code rather than fiddling around with makefiles.
Software installation is another major source of headaches; a poorly written installation setup can lead to a package that won't run or install on the user's system. A crabby, frustrated user may never touch your software package again, regardless of the amazing wonders it can perform once it's up and run- ning. New software projects have enough to worry about, without alienating potential users. A clean, simple, reliable installation gives your software a professional appearance and will lead to return customers.
The three main components of the GNU build system are autoconf, automake, and libtool. We'll explore the ins and outs of each of these components in this chapter. These tools also come with extensive documentation, available through the info command-for example, info autoconf.
The Configuration Script
If you've installed many open-source software packages, you've probably run across the popular configure script. This configuration script automatically scans your system, running a series of checks, compiling and running little test programs, and reporting all the results to the software package you're trying to install. The new software can then use this information to tune itself to the particular quirks of your system.
The configuration script is very handy when it comes to porting your application to different brands of UNIX. For example, if you wanted to use a somewhat exotic function call from the C library but knew it wasn't supported on all platforms, you could check for it in the configuration script. If the configuration script found the function call on system A, your code could use it directly. However, if the function call didn't exist on system B, you could provide a fallback routine to use instead. All of this would happen at compile time, on the target system. Obviously this type of configuration script would not work with binary-only software. It is practical only when you can use it to tweak the compile settings and react to it at the source code level.
Running configure
The following series of commands is all the user needs to do to set up, compile, and install most software distributions created with the autoconf system. The commands are always the same, so the process is easily predictable for the inexperienced installer. The only thing different between packages is that there are extra command line options you can use with configure.
$ ./configure
$ make
$ make install
|
All GNU-based configure scripts come with a basic set of command line parameters; you can get a list of them at any time by typing in
$ ./configure --help
|
You can use these parameters to control where configure installs the software, which extra components to use (or not use), how much debug information to generate, and where to find external libraries and header files. The package owner can also add new parameters to handle special situations unique to a software package. All these parameters have sensible defaults, so it's usually a safe bet to run configure with no parameters. In normal usage, you'll probably need to include only the --prefix parameter, if you want to change the target install location. By default, configure puts things in the /usr/local directory. If you wanted to install the software in a special directory-for example, if it was beta software, or just something you didn't want polluting your normal install directories-you might do something like this:
$ ./configure --prefix=/custom/path
|
configure would then install the software into /custom/path/bin, /custom/path/lib, and the like. If you decided to keep the software, you could run configure again without the --prefix option and rebuild, and it would install things into /usr/local/bin, /usr/local/lib, and so on.
That's a lot of black magic, right? You're probably wondering how it all works, and how hard it would be to create a configure script for your own project. At its essence, the configure script is nothing more than a long, complex shell script. If you had to write it by hand, you would spend half your time debugging it and converting it for new projects. Fortunately, the GNU build system provides a simple-to-use set of tools for automatically generating configure scripts (and much more). We'll explore these tools in Sections 3.2 and 3.3.
Inside the configure Script
For now, let's create a minimal configure script and see what it looks like. Create a temporary directory somewhere, and then run the following commands:
$ echo "AC_INIT(main.c)\nAC_OUTPUT(Makefile)" > configure.in
$ cat configure.in
AC_INIT(main.c)
AC_OUTPUT(Makefile)
$ touch main.c Makefile.in
$ autoconf
$ ls -l
-rw-rw-r-- 1 jsheets jsheets 0 Jul 3 14:52 Makefile.in
-rwxrwxr-x 1 jsheets jsheets 26817 Jul 3 14:52 configure*
-rw-rw-r-- 1 jsheets jsheets 36 Jul 3 14:52 configure.in
-rw-rw-r-- 1 jsheets jsheets 0 Jul 3 14:52 main.c
|
The autoconf command parses the configure.in macro file and expands it into the configure shell script file. But look at the size of it: 26,000 bytes- almost 800 lines for a script that doesn't do anything. Where is autoconf getting all those bytes?
Take a look at it in your favorite editor. You'll see a very long list of variable declarations, most of them at first glance quite cryptic. You'll also see the code that generates the --help listing. The configure script is pretty well commented, so if you're curious about how it works, you should be able to learn a lot by studying it. Of particular note are the last couple hundred lines of the file; this code creates two files: config.cache and config.status. The first is a temporary file for storing the test results between successive calls to configure, so that configure doesn't have to run time-consuming tests every time. If configure finds the results of a test in config.cache, it grabs the results from there rather than running the test again.
The second file, config.status, is another shell script, used to convert foo.in files into foo files by performing variable substitution (as described in Section 3.1.3). Most of this processing is simple text replacement, to customize certain files according to configure's test results. For example, if configure discovers that a system uses the GNU gawk tool instead of the standard variant, awk, it can insert the string "gawk" directly into the Makefile file on that system.
Most of the time you won't have to worry about these two files. You'll just run configure, and configure will take care of the rest. If you make a change to configure.in that involves a cached test result, you may have to delete the old config.cache file to force configure to run the test again from scratch. The only time you would want to run config.status by hand might be to regenerate your makefiles according to the current set of configure options; if you modified a makefile during testing and wanted to restore it, you could delete it and then run config.status to recreate it in its original form from the Makefile.in file.
Let's try running the configure script we created earlier. Here's a sample session:
$ ./configure
creating cache ./config.cache
updating cache ./config.cache
creating ./config.status
creating Makefile
$ ls -lt
-rw-rw-r-- 1 jsheets jsheets 0 Jul 3 14:58 Makefile
-rw-rw-r-- 1 jsheets jsheets 127 Jul 3 14:58 config.log
-rw-rw-r-- 1 jsheets jsheets 768 Jul 3 14:58 config.cache
-rwxrwxr-x 1 jsheets jsheets 4576 Jul 3 14:58 config.status*
-rwxrwxr-x 1 jsheets jsheets 26817 Jul 3 14:52 configure*
-rw-rw-r-- 1 jsheets jsheets 0 Jul 3 14:52 Makefile.in
-rw-rw-r-- 1 jsheets jsheets 0 Jul 3 14:52 main.c
-rw-rw-r-- 1 jsheets jsheets 36 Jul 3 14:52 configure.in
|
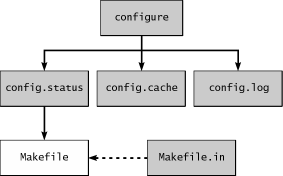
We have four new files. Figure 3.1 shows the process graphically. Aside from the config.cache and config.status files we saw in the configure listing, we also see the config.log file (empty except for the opening comments because we didn't run any real tests), and the Makefile file generated from Makefile.in. The config.log file is good for debugging the configuration process. As configure chugs along, it dumps its test results into config.log. When tests fail with cryptic errors, you can often find out more about the failure by looking at this file.
Makefile Variable Substitution
Since our Makefile.in file in Section 3.1.2 was empty, the output file, Makefile, was also empty. Let's try putting something in Makefile.in to see what we get. We'll start with a simple comment:
$ echo "# This is Makefile.in" > Makefile.in
$ ./configure
loading cache ./config.cache
creating ./config.status
creating Makefile
$ cat Makefile
# Generated automatically from Makefile.in by configure.
# This is Makefile.in
|
The entire contents of Makefile.in were copied into Makefile, along with a reminder that the Makefile was not handwritten.
Next we'll attempt some variable substitution to see how configure passes information to your compiler. This is where things start to get a little more complex. The first step is to add the variable substitution to configure.in. The next time the autoconf script parses configure.in, the new variable will show up in the configure script as part of config.status. Since config.status creates the makefiles, it must also handle the variable substitutions. So let's get started. Change your configure.in file to look like Listing 3.1.
Listing 3.1 configure.in with Variable Substitutions
AC_INIT(main.c)
VERSION="0.0.1"
AC_SUBST(VERSION)
AC_OUTPUT(Makefile)
|
VERSION will become a shell script variable in configure. Anything that is not a special macro will be copied verbatim from configure.in to configure. But this is not what we want. As soon as configure is done running, the shell process will die and the value of VERSION will be lost. That's where the AC_SUBST macro comes into play. AC_SUBST adds VERSION to the list of variables on which substitutions will be performed. In fact, all substitutions in config.status are put there by AC_SUBST at some time or another.
To make sure the wrong substitutions don't take place, config.status looks only for variables delimited with the symbol @. Thus to substitute the value of our VERSION shell script variable into Makefile, we must refer to it as "@VERSION@" in Makefile.in. Perform the following commands to see how it works:
$ echo "# Makefile for version @VERSION@" > Makefile.in
$ echo "VERSION = @VERSION@" >> Makefile.in
$ cat Makefile.in
# Makefile for version @VERSION@
VERSION = @VERSION@
$ autoconf
$ ./configure
loading cache ./config.cache
creating ./config.status
creating Makefile
$ cat Makefile
# Generated automatically from Makefile.in by configure.
# Makefile for version 0.0.1
VERSION = 0.0.1
|
Remember, if you fail to run autoconf after altering configure.in, none of your changes will propagate to your makefiles.