Chapter 2. The GTK+/GNOME System
Although it's possible to write an application using only raw Xlib calls and ANSI C functions, it's not something you would normally want to do unless you had no other choice. For each application, you'll end up implementing your own event-polling loop, your own data structures, and very likely your own widget system-all from scratch. Other widget toolkits exist, like Motif and Xt, but they may not be what you're looking for either.
When the original GIMP developers began their project, they looked at the current toolkits and decided that it was better to start from scratch. In a decision that would eventually affect thousands of free-software developers, they chose to extract all the widget-related code from the GIMP and put it into a standalone set of libraries called GTK.1 Later the GNOME team added other layers and libraries, which we'll introduce in this chapter and explore throughout the rest of the book.
Unfortunately, a detailed description of GTK+ is beyond the scope of this book. You can read the online documentation at http://www.gtk.org/rdp; you can also learn a lot from looking at the source code for existing GNOME and GTK+ applications.
GLib
GLib is a tight little library, full of generic data-handling functions; it also provides other abstractions to make porting and cross-platform development easier, such as generic data types, thread support, dynamic library loading, and even a lexical scanner. GLib forms the solid, portable base upon which GTK+, ORBit, and GNOME rest.
Simple Data Types
Data is the currency of all applications. All variables you use must have an explicit data type (at least in strictly typed languages like C and C++; not all languages are so strict about it). The C language comes with a comprehensive set of these data types, including int, char, long, and double, among others. C's data types can express just about any fundamental flavor of data you'll come across, but they don't protect us from all the dangers that might arise. C is deliberately vague on the sizes of certain data types, particularly the int type. The bit size of the int type might be different on different platforms. Simply recompiling the same code on a different platform can change the behavior of your program in subtle ways. On a 64-bit platform, 3 billion might be a valid value for your int; on a 32-bit platform, however, 3 billion might overflow the bounds of the data type, leaving you with a bogus value.
GLib defines a complete set of data types that you can use in your applications to make it easier to port to different platforms. When you use these data types, you insulate your applications from the details of each new architecture. You no longer have to worry about whether an integer type is 32 bits or 64 bits, or what native type to use for your Boolean variables. When GLib is installed on a new system, it uses the autoconf system to probe for the exact sizes of the various data types and makes the proper typedef assignments for you.
If you want exactly a 16-bit unsigned integer, GLib has a data type for that, guint16. If instead you need a 64-bit signed integer, GLib has the data type gint64 for you. Rather than leaving it up to you to guess how many bits an integer holds, GLib announces it right in the data type. Other data types are gint, guint32, gboolean, glong, gdouble, and so on. Most of them are typedef instances of standard C types. See the GLib documentation for a more complete listing of GLib's types.
Namespaces
GLib, GTK+, and GNOME all use a simple, consistent function-naming convention of the form namespace_object_operation( ). Thus all functions are named from left to right, according to scope. All GLib functions are prefixed with a namespace of "g," all GTK+ functions are prefixed with "gtk," and all GNOME functions use the "gnome" namespace.
The second part of the function name is always the object name, which usually indicates which data structure the function will operate on. For example, all gtk_widget_* functions operate on a GtkWidget structure supplied as the first parameter to the function.
The function name ends with the operation to perform. Depending on the particular operation, the function may or may not have additional parameters beyond the first object parameter. Here are a couple examples that operate on the GtkWidget structure:
void gtk_widget_show(GtkWidget *widget);
void gtk_widget_set_sensitive(GtkWidget *widget,
gboolean sensitive);
|
Logging
When things go wrong in your application, it's nice to have a way to communicate with your users about the problem. Some of this communication will take the form of graphical dialog boxes (see Chapter 7). These pop-up windows are good for warnings, error messages, and spontaneous data gathering, but by their nature they don't leave a trace of their passing. If something goes horribly awry and the only response is an error dialog, the user will have to quickly grab a piece of paper and write down the error before closing the window. Sometimes you just want to output text messages to stdout (the text console), or permanently to a log file. GLib has a nice, configurable set of logging func- tions that allow you to do this in a flexible, portable way.
Traditionally, C applications use some form of the printf( ) function to write messages to the console. Alternatively, variations of write( ) and fprintf( ) can send the same messages to a file. If you wanted to reroute your logging messages between these two output styles at runtime, you would have to write a wrapper logging function to handle the logic, and call the wrapper instead of calling printf( ) and write( ) directly. This is exactly what GLib does.
The four main logging functions are, in increasing order of severity,
void g_print(const gchar *format, ...);
void g_message(const gchar *format, ...);
void g_warning(const gchar *format, ...);
void g_error(const gchar *format, ...);
|
They behave just like a normal printf( ) statement:
g_message("%d bottles of beer left in the fridge", num_bottles);
|
Notice that for g_message( ), g_warning( ), and g_error( ), you don't need to worry about line breaks. If you include the character "\n" at the end of your format strings, you'll end up with double spacing between log messages.
Each of these four logging channels handles its formatted messages in its own particular way. By default, all four channels write to the stdout of the console the application was run from. The g_print( ) function passes the text on without changing it; the other three add a little extra formatting to indicate the severity of the message to the user. In addition to printing a logging message, the g_error( ( )) function calls abort( ), which brings your program to a screeching halt.
It's also possible to intercept these logging messages and handle them in a custom manner, most likely sending them to a file rather than to stdout. You can override each logging channel separately-for example, if you want to send the output of only g_message( ) to a file, leaving the other channels alone. The handler function prototype and the GLib function you call to set it up look like this:
typedef void (*GLogFunc)(const gchar *log_domain,
GLogLevelFlags log_level, const gchar *message,
gpointer user_data);
guint g_log_set_handler(const gchar *log_domain,
GLogLevelFlags log_levels, GLogFunc log_func,
gpointer user_data);
|
The GLogLevelFlags parameter is an enum of bit flags that define the character and specific channel of a logging message. The three you'll most likely use with logging handlers are G_LOG_LEVEL_MESSAGE, G_LOG_LEVEL_WARNING, and G_LOG_LEVEL_ERROR. Since they are bit flags, you can use a binary OR operator to combine more than one channel into a single handler. Listing 2.1 shows how to send g_message( ) and g_warning( ) to a log file, myapp.log.
Listing 2.1 Overriding a Logging Handler
void LogToFile (const gchar *log_domain, GLogLevelFlags log_level,
const gchar *message, gpointer user_data)
{
FILE *logfile = fopen ("myapp.log", "a");
if (logfile == NULL)
{
/* Fall back to console output if unable to open file */
printf ("Rerouted to console: %s\n", message);
return;
}
fprintf (logfile, "%s\n", message);
fclose (logfile);
}
int main(int argc, char *argv[])
{
...
/* Send g_message( ) and g_warning( ) to the file */
g_log_set_handler (NULL, G_LOG_LEVEL_MESSAGE |
G_LOG_LEVEL_WARNING, LogToFile, NULL);
...
}
|
The g_print( ) function has its own set of override functions, which behave pretty much the same. The g_set_print_handler( ) function returns the old g_print( ) handler, in case you want to restore it later.
typedef void (*GPrintFunc)(const gchar *string);
GPrintFunc g_set_print_handler(GPrintFunc func);
|
Containers
GLib has many valuable container types, including linked lists, strings, arrays, and binary trees, with a wide range of functions to manipulate them all. We don't have nearly enough space to go into them in any depth; such a pursuit could easily take up an entire chapter. A quick tour will suffice to give you a feel for what GLib has to offer. You can peruse the GLib documentation to find out in greater detail how to use these functions.
The simplest container is a string. GLib offers two types of string support. The first category of string functions consists of wrapper functions around common UNIX-style string functions that may or may not exist on all plat- forms, such as g_snprintf( ), g_strcasecmp( ), g_strdup( ), and g_strconcat( ). All of these functions act directly on gchar* strings.
The string functions of the other category perform actions on GLib's abstract string wrapper, GString:
typedef struct _GString GString;
struct _GString
{
gchar *str;
gint len;
};
|
All of these functions have the form g_string_*, such as g_string_new( ), g_string_sprintf( ), g_string_append( ), g_string_free( ), and so on. You can use the g_string_* functions to operate opaquely on a GString structure (the preferred method), or you can access the structure members directly and use the normal UNIX-flavor string functions, although you should be careful to keep the len field in sync with the str field if you make changes to it.
GLib has three types of array containers: GArray, GByteArray, and GPtrArray. Each array expands and shrinks automatically as you add and remove elements, thus insulating you from the boring and potentially dangerous responsibility of maintaining your arrays. As with most GLib containers, you create them with a _new( ) function and release them with a _free( ) function. Each array also has various append, prepend, add, remove, and accessor functions. The array containers can grow and shrink automatically as you add and remove elements.
GArray, the most generic array, stores arbitrary, uniformly sized elements. When you create the GArray, you must specify the size the elements will be. When you add new elements, GLib copies them directly into the GArray, after which you can delete the original copies. GByteArray is a special case of GArray in which the size of each element is hard-coded to a single byte. GPtrArray is another special case of GArray in which each element is a pointer that (theoretically) points to a chunk of data outside the array. When you free a GArray or GByteArray, GLib automatically cleans up all the data inside the ar- ray. Conversely, when you free a GPtrArray, GLib always cleans up the memory for the pointers themselves, but may or may not clean up the external (pointed to) data; the g_ptr_array_free( ) function contains a Boolean parameter to specify whether or not you want to also free up the external data.
GLib comes with two types of linked-list containers: singly linked (GSList) and doubly linked (GList). The only difference between the two is the number of directions in which you can iterate over the elements (see Figure 2.1). A singly linked list allows one direction: forward only. A doubly linked list allows both directions: forward and backward. The concept of a linked list is very simple. Each element of a linked list contains a pointer to the data, plus a pointer to the next (or previous) element. All elements are connected together in a consecutive chain.
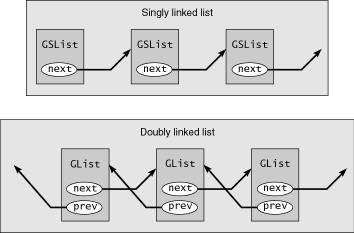
Because each element knows about only its immediate neighbors, you can easily insert elements at the beginning, middle, or end of the list, without moving all the others around. This is much more efficient than insertion into an array, in which case you must displace every element between the new element and the end of the array. On the other hand, random access is more expensive with linked lists. If you want to find the thirteenth element, for example, you must pass through each of the first 12 elements in the chain to get to the one you want. Since arrays are laid out in contiguous memory, you can calculate the exact position of the thirteenth element with a little pointer math and go right to it. Which type of container you use should depend on how you expect to manipulate the data.
A singly linked list element looks like this:
struct GSList
{
gpointer data;
GSList *next;
};
|
A doubly linked list is almost identical. The only difference is a second list pointer, to the previous element.
struct GList
{
gpointer data;
GList *next;
GList *prev;
};
|
The data field is a generic void* pointer, so you'll need to cast it to the proper data type before using it. You can iterate through the elements by cycling through the next field. Creating a linked list with GLib is simple. You just start adding elements to a NULL list pointer; GLib will allocate new elements for you and load your data into them as it goes.
Both types of linked lists have the same basic API. Singly linked list functions have the prefix g_slist_; doubly linked lists have the prefix g_list_. Otherwise, the two function sets look and behave the same (although for obvi- ous reasons GSList is lacking the g_list_previous( ) function of GList).
Another common type of data container is the hash table (see Figure 2.2). Hash tables are good for storing nonsequential data and accessing it randomly. Each piece of data is associated with a key, which is usually a string or an inte- ger that uniquely identifies that piece of data. For example, you might use an employee's name (or ID number) as a key to looking up the data structure of his or her employee information. Each key can refer to only one data item, so if you save two pieces of data to the same key, the second item overwrites the first. The number of keys always exactly matches the number of data items stored in the hash table.
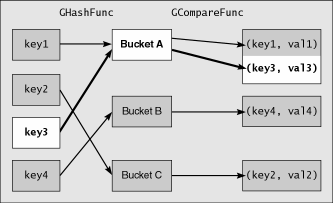
To keep things efficient, the keys are hashed, or converted, into an integer value with the GHashFunc algorithm, which is then used for lookups. This hash value may or may not be unique among all possible keys. When collisions occur and more than one key results in the same hash value, GLib's GHashTable will form a bucket, or a linked list of data items that correspond to the same hash value. Such is the case in Figure 2.2, in which keys 1 and 3 share the same hash value and are thus stored in the same bucket. To figure out which value in the bucket refers to which key, you must supply a GCompareFunc callback to test for equality between two keys. In Figure 2.2, when looking up key 3, GLib will run the GCompareFunc on key 3 versus each key in bucket A-that is, GCompareFunc(key3, key1), then GCompareFunc(key3, key3)-until it finds a match.
guint (*GHashFunc) (gconstpointer key);
gint (*GCompareFunc) (gconstpointer a, gconstpointer b);
|
As we've seen, GLib's implementation of hash tables is very generic and allows you to declare your own hash and comparison functions. If you are writing your own hashing functions, you should do your best to avoid creating duplicate hash values, in order to keep the buckets from filling up. For example, if your hashing algorithm used only the first four characters of a string-based key, any lookups of keys that started with the same four characters would result in a bucket collision, which would degrade performance of the hash table. Thus a lookup of the key "mythic" would return the same hash value as a lookup of "mythological" and "mythos." Each time you performed a lookup on one of these keys, GLib would have to sift through the linked list of "myth" keys in that bucket.
To save you the trouble of creating algorithms for the most common types of keys, GLib supplies a handful of prespun hashing functions. You must specify the hashing function when you create the hash table, and you cannot change it later. The GHashTable structure holds the data used by the hash table; you should always use the g_hash_table_* functions to access it. The GHashTable structure is classified as opaque, so you should never access its fields directly.
Hash tables are neat and pretty efficient, but they do have their limitations. Even though the keys are reduced to integer values, the hash table must cycle through them sequentially when performing lookups. The contents are not sorted, and no guarantees can be made regarding the order of the elements. Lookup times will depend on the hashing function you use, the number of hash collisions in your data set, and the order in which you happened to add the elements.
The balanced binary tree (GTree) is in a sense a specialized version of a hash table, with its own peculiar quirks. While the hash table is fundamentally an optimized list container, the binary tree is a sorted hierarchical container. Each time you add an element to the binary tree, the tree adjusts itself to make the next lookup operation as efficient as possible. Each node on the tree can have at most two branches (or nodes). Each subnode can in turn have two branches (nodes) of its own, and so on. The tree struggles to keep both sides of every branch balanced. If you add nodes to the left side of a tree, the tree will shuffle things around so that both sides contain a similar number of nodes.
Thus while the hash table is optimized for faster single key comparisons but may end up traversing an inefficient number of elements for each lookup, the binary tree is optimized for the fewest number of traversals possible. You can customize the way in which the binary tree distributes its nodes by changing the sorting algorithm.
Although, technically speaking, binary trees have a hierarchical structure, you as a programmer don't explicitly benefit from it. Your lookups are faster, and you have more sorting and traversal options, but you don't really have di- rect control over where your data ends up in the tree. Inserting a new element into a binary tree may trigger a massive shuffling of branches as the tree struggles to rebalance itself. Parents may switch positions with children or move farther down the hierarchy. You can depend on the fact that, for example, a certain element will always remain on the left side of another element, but not how far to the left.
GNode, GLib's n-ary tree container, gives you this critical control. If you put a GNode at a certain place in the tree, it will stay there until you move it. Furthermore, any element in a GNode tree can have a potentially unlimited number of children or siblings (although each element should only have one parent). In a sense, the GNode is similar to a two-dimensional doubly linked list, in which you can iterate from sibling to sibling and from parent to child (see Figure 2.3).
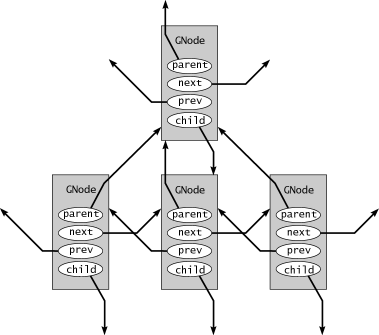
We've covered a lot of ground in this section without showing a single scrap of useful container code. You may not have learned much about how to write code for GLib's many containers, but hopefully you now have a better idea of how they work. This should make it much easier to understand the containers' APIs. The online GLib documentation covers all of this in much greater detail.
Other Toys
GLib isn't just a reservoir for data containers and portability wrappers. It also harbors a surprising range of useful tools and utilities. Not only does it provide generic abstractions for threads, dynamically loaded modules, and input/output handling, but it also contains such gems as a full-featured event loop (used extensively by GTK+) and a lexical scanner for parsing through text streams.
Thread handling is a very complicated affair, far beyond the scope of this book. We'll touch on it only lightly here. GLib's thread implementation is by no means comprehensive, or particularly advanced; in fact, it is only just enough to make GLib thread-safe. It covers the basics in a clear, simple manner, providing thread synchronization through mutexes (GMutex and GStaticMutex) and thread-local data (GPrivate and GStaticPrivate), al- though at this time it does not contain functions to create and destroy the threads. You'll have to use your operating system's thread API directly for that. GLib's GThread implementation resides in a standalone library, libgthread, and is more or less just a wrapper around the native thread library-for example, libpthread.
GLib's GModule interface provides a portable wrapper around the dynamic module-loading APIs of most modern operating systems, including Linux, Solaris, IRIX, HP/UX, and even Microsoft Windows (as DLL, Dynamic Link Library, files). You can use it to load in libraries at runtime-for example, as part of a plug-in architecture, like the countless graphics filters in the GIMP drawing application. Using the GModule functions, you can load up a dynamic module, search for specific functions inside it, invoke those functions, and then close the module. GModule insulates you from the often vast differences in dynamic loading between platforms and leads to more portable code. Like GThread, the GModule implementation resides in its own library, libgmodule.
GLib also contains a handful of dynamic memory management functions, in the form of wrappers around the standard C memory functions. You can use g_new( ) and g_malloc( ) to freshly allocate memory, g_new0( ) and g_malloc0( ) to allocate memory initialized to zeros, and g_renew( ) and g_realloc( ) to reallocate existing memory to a different size. The g_free( ) function cleans up the memory, regardless of which GLib function you used to allocate it. The optional functions g_mem_profile( ) and g_mem_check( ) provide you with feedback on the currently allocated memory, although since these functions introduce a performance penalty, you'll have to compile your version of GLib with the configure script options --enable-mem-profile and --enable-mem-check to use them.
If you plan on allocating and freeing lots of small chunks of memory, you might want to look into GLib's block memory support. GMemChunk allocates a single chunk of memory to store many smaller, contiguous objects. It handles the memory management for you, keeping track of which chunks are in use and which chunks have been freed. When you request a new chunk of memory, GMemChunk gives you a pointer to an existing slice of its larger block, rather than allocating new memory with the more costly call to g_malloc( ). GLib uses GMemChunk internally, for its linked list and GNode data containers.
The GIOChannel interface is a wrapper around standard UNIX files, sockets, and pipes that brings consistency and portability to the methods you use to handle these file descriptors. GIOChannel also helps integrate input/output polling and callbacks into GLib's event loop. This feature will come in handy if your application needs to periodically check on a socket or pipe connection without blocking each time (which would interfere with your application's repainting and responsiveness), or monitor a file for changes. You'll have to create the file descriptor yourself (unless you're using stdin, stdout, or stderr), but once you wrap it in a GIOChannel, you can use GLib to wire it into the event loop for callback notifications, to read and write from it, and to close it when you're done. GIOChannel also supports reference counting, in case you need to share a channel with more than one object.
The GMainLoop event loop is the heartbeat of most GTK+ and GNOME applications. The event loop cycles continuously through its iterations, nudging all the various hooks and event streams you've installed into it. The event loop is like a many-armed conductor sitting at the center of your application, letting you know when important things happen. You can set up polling events based on file descriptors (e.g., with GIOChannel), timers to synthesize periodic events, and even generic event sources (like the GDK event queue). You can also prioritize your event sources so that, for example, a certain socket event takes priority over certain timer events. If you have any low-priority maintenance routines that you want to run in the background, you can install them as idle handlers in the event loop. When the event loop runs out of events, it will spend its time running the idle functions. GMainLoop is ex- tremely versatile and can be used in virtually any event-driven software. It was originally part of GTK+, but later it was abstracted and pulled into GLib to make it available to applications outside of GTK+.
Moving along, the lexical scanner, GScanner, is a generic, configurable text-parsing tool. It's good for reading in configuration files, which is exactly what GTK+ uses it for. GTK+ reads in a text-based gtkrc file each time you start up an application; the user can define the appearance and behavior of GTK+ in the gtkrc file. GScanner recognizes a wide assortment of common tokens, like curly braces, numbers, characters, commas, and even various styles of comments. You can also define custom symbols, or tokens, if the basic set doesn't cover your needs. By tweaking the contents of the GScannerConfig structure and passing it on to GScanner, you can exert very fine control over which tokens the lexical scanner will acknowledge and how it reacts to different combinations of tokens. Once the GScanner is set up, you can repeatedly call the g_scanner_get_next_token ( ) function to grab tokens one at a time until you're finished, or until you reach the end of the file. GLib's lexical scanner is surprisingly powerful for such a small, rarely used bit of code. The interface is admittedly a little cryptic, and the documentation is a bit thinner than it could be, but it's quite easy to use once you grasp how it works. For a working example, take a look at the file gtk+/gtk/gtkrc.c in the GTK+ source code distribution.
Future versions of GTK+, starting with GTK+ 2.0, will contain the GObject infrastructure, for managing object-oriented systems. GObject is essentially the GTK+ object system ripped out of GTK+ and made available to non-GTK+ applications, much as the GTK+ main loop was extracted and put into GMainLoop.