第1章 Erlang教程¶
| 翻译: | 连城 |
|---|
串行编程¶
程序1.1用于计算整数的阶乘:
程序1.1
-module(math1).
-export([factorial/1]).
factorial(0) -> 1;
factorial(N) -> N * factorial(N - 1).
函数可以通过shell程序进行交互式求值。 Shell会提示输入一个表达式,并计算和输出用户输入的任意表达式,例如:
> math1:factorial(6).
720
> math1:factorial(25).
15511210043330985984000000
以上的“>”代表 shell 提示符,该行的其他部分是用户输入的表达式。之后的行是表达式的求值结果。
factorial 的代码如何被编译并加载至 Erlang 系统中是一个实现相关的问题。 [1]
在我们的例子中,factorial函数定义了两个子句:第一个子句描述了计算factorial(0)的规则,第二个是计算factorial(N)的规则。当使用某个参数对factorial进行求值时,两个子句按照它们在模块中出现的次序被依次扫描,直到其中一个与调用相匹配。当发现一个匹配子句时,符号->右边的表达式将被求值,求值之前函数定义式中的变量将被代入右侧的表达式。
所有的 Erlang 函数都从属于某一特定模块。最简单的模块包含一个模块声明、导出声明,以及该模块导出的各个函数的实现代码。导出的函数可以从模块外部被调用。其他函数只能在模块内部使用。
程序1.2是该规则的一个示例。
程序1.2
-module(math2).
-export([double/1]).
double(X) ->
times(X, 2).
times(X, N) ->
X * N.
函数double/1可在模块外被求值[2],times/2则只能在模块内部使用,如:
> math2:double(10).
20
> math2:times(5, 2).
** undefined function: math2:times(5,2) **
在程序1.2中模块声明-module(math2)定义了该模块的名称,导出属性-export([double/1])表示本模块向外部导出具备一个参数的函数double。
函数调用可以嵌套:
> math2:double(math2:double(2)).
8
Erlang 中的选择是通过模式匹配完成的。程序 1.3 给出一个示例:
程序1.3
-module(math3).
-export([area/1]).
area({square, Side}) ->
Side * Side;
area({rectangle, X, Y}) ->
X * Y;
area({circle, Radius}) ->
3.14159 * Radius * Radius;
area({triangle, A, B, C}) ->
S = (A + B + C)/2,
math:sqrt(S*(S-A)*(S-B)*(S-C)).
如我们所期望的,对math3:area({triangle, 3, 4, 5})得到6.0000而math3:area({square, 5})得到 25 。程序1.3 引入了几个新概念:
元组——用于替代复杂数据结构。我们可以用以下 shell 会话进行演示:
> Thing = {triangle, 6, 7, 8}. {triangle, 6, 7, 8} > math3:area(Thing). 20.3332此处Thing被绑定到{triangle, 6, 7, 8}——我们将Thing称为尺寸为4的一个元组——它包含 4 个元素。第一个元素是原子式triangle,其余三个元素分别是整数6、7和8。
模式识别——用于在一个函数中进行子句选择。area/1被定义为包含4个子句。以math3:area({circle, 10})为例, 系统会尝试在area/1定义的子句中找出一个与{circle, 10}相符的匹配,之后将函数定义头部中出现的自由变量Radius绑定到调用中提供的值(在这个例子中是10)。
序列和临时变量——这二者是在area/1定义的最后一个子句中出现的。最后一个子句的主体是由两条以逗号分隔的语句组成的序列;序列中的语句将依次求值。函数子句的值被定义为语句序列中的最后一个语句的值。在序列中的第一个语句中,我们引入了一个临时变量S。
数据类型¶
Erlang 提供了以下数据类型:
常量数据类型——无法再被分割为更多原始类型的类型:
- 数值——如:123、-789、3.14159、7.8e12、-1.2e-45。数值可进一步分为整数和浮点数。
- Atom——如:abc、'An atom with spaces'、monday、green、hello_word。它们都只是一些命名常量。
复合数据类型——用于组合其他数据类型。复合数据类型分为两种:
- 元组——如:{a, 12, b}、{}、{1, 2, 3}、{a, b, c, d, e}。元组用于存储固定数量的元素,并被写作以花括号包围的元素序列。元组类似于传统编程语言中的记录或结构。
- 列表——如:[]、[a, b, 12]、[22]、[a, 'hello friend']。列表用于存储可变数量的元素,并被写作以方括号包围的元素序列。
元组合列表的成员本身可以是任意的 Erlang 数据元素——这使得我们可以创建任意复杂的数据结构。
在 Erlang 中可使用变量存储各种类型的值。变量总是以大写字母开头,例如,以下代码片段:
X = {book, preface, acknowledgements, contents,
{chapters, [
{chapter, 1, 'An Erlang Tutorial'},
{chapter, 2, ...}
]
}},
创建了一个复杂的数据结构并将其存于变量X中。
模式识别¶
模式识别被用于变量赋值和程序流程控制。Erlang是一种单性赋值语言,即一个变量一旦被赋值,就再也不可改变。
模式识别用于将模式与项式进行匹配。如果一个模式与项式具备相同的结构则匹配成功,并且模式中的所有变量将被绑定到项式中相应位置上出现的数据结构。
函数调用中的模式识别¶
程序1.4定义了在摄氏、华氏和列式温标间进行温度转换的函数convert。convert的第一个参数是一个包含了温标和要被转换的温度值,第二个参数是目标温标。
程序1.4
-module(temp).
-export([convert/2]).
convert({fahrenheit, Temp}, celsius) ->
{celsius, 5 * (Temp - 32) / 9};
convert({celsius, Temp}, fahrenheit) ->
{farenheit, 32 + Temp * 9 / 5};
convert({reaumur, Temp}, celsius) ->
{celsius, 10 * Temp / 8};
convert({celsius, Temp}, reaumur) ->
{reaumur, 8 * Temp / 10};
convert({X, _}, Y) ->
{cannot,convert,X,to,Y}.
对convert进行求值时,函数调用中出现的参数(项式)与函数定义中的模式进行匹配。当找到一个匹配时,“->”右侧的代码便被求值,如:
> temp:convert({fahrenheit, 98.6}, celsius).
{celsius,37.0000}
> temp:convert({reaumur, 80}, celsius).
{celsius,100.000}
> temp:convert({reaumur, 80}, fahrenheit).
{cannot,convert,reaumur,to,fahrenheit}
匹配原语“=”¶
表达式Pattern = Expression致使Expression被求值并尝试与\ Pattern 进行匹配。匹配过程要么成功要么失败。一旦匹配成功,则Pattern中所有的变量都被绑定,例如:
> N = {12, banana}.
{12,banana}
> {A, B} = N.
{12,banana}
> A.
12
> B.
banana
匹配原语可用于从复杂数据结构中拆分元素。
> {A, B} = {[1,2,3], {x,y}}.
{[1,2,3],{x,y}}
>A.
[1,2,3]
>B.
{x,y}
> [a,X,b,Y] = [a,{hello, fred},b,1].
[a,{hello,fred},b,1]
> X.
{hello,fred}
> Y.
1
> {_,L,_} = {fred,{likes, [wine, women, song]},
{drinks, [whisky, beer]}}.
{fred,{likes,[wine,women,song]},{drinks,[whisky,beer]}}
> L.
{likes,[wine,women,song]}
下划线(写作“_”)代表特殊的匿名变量或无所谓变量。在语法要求需要一个变量但又不关心变量的取值时,它可用作占位符。
如果匹配成功,定义表达式Lhs = Rhs的取值为Rhs。这使得在单一表达式中使用多重匹配成为可能,例如:
{A, B} = {X, Y} = C = g{a, 12}
“=”是右结合操作符,因此A = B = C = D被解析为A = (B = (C = D))。
内置函数¶
有一些操作使用Erlang编程无法完成,或无法高效完成。例如,我们无法获悉一个原子式的内部结构,或者是得到当前时间等等——这些都属于语言范畴之外。因此Erlang提供了若干内置函数(built-in function, BIF)用于完成这些操作。
例如函数atom_to_list/1将一个原子式转化为一个代表该原子式的(ASCII)整数列表,而函数date/0返回当前日期:[*]
> atom_to_list(abc).
[97,98,99]
> date().
{93,1,10}
BIF的完整列表参见附录??。
并发¶
Erlang是一门并发编程语言——这意味着在Erlang中可直接对并行活动(进程)进行编程,并且其并行机制是由Erlang而不是宿主操作系统提供的。
为了对一组并行活动进行控制,Erlang提供了多进程原语:spawn用于启动一个并行计算(称为进程);send向一个进程发送一条消息;而receive从一个进程中接收一条消息。
spawn/3启动一个并发进程并返回一个可用于向该进程发送消息或从该进程接收消息的标识符。
Pid ! Msg语法用于消息发送。Pid是代表一个进程的身份的表达式或常量。Msg是要向Pid发送的消息。例如:
Pid ! {a, 12}
表示将消息{a, 12}发送至以Pid为标识符的进程(Pid是进程标识符process identifier的缩写)。在发送之前,消息中的所有参数都先被求值,因此:
foo(12) ! math3:area({square, 5})
表示对foo(12)求值(必须返回一个有效的进程标识符),并对math3:area({square, 5})求值,然后将计算结果(即25)作为一条消息发送给进程。send原语两侧表达式的求值顺序是不确定的。
receive原语用于接收消息。receive语法如下:
receive
Message1 ->
... ;
Message2 ->
... ;
...
end
这表示尝试接收一个由Message1、Message2等模式之一描述的消息。对该原语进行求值的进程将被挂起,直至接收到一个与Message1、Message2等模式匹配的消息。一旦找到一个匹配,即对“->”右侧的代码求值。
接收到消息后,消息接收模式中的所有未绑定变量都被绑定。
receive的返回值是被匹配上的接收选项所对应的语句序列的求值结果。
我们可以简单认为send发生一条消息而receive接收一条消息,然而更准确的描述则是send将一条消息发送至一个进程的邮箱,而receive尝试从当前进程的邮箱中取出一条消息。
receive是有选择性的,也就是说,它从等候接收进程关注的消息队列中取走第一条与消息模式相匹配的消息。如果找不到与接收模式相匹配的消息,则进程继续挂起直至下一条消息到来——未匹配的消息被保存用于后续处理。
一个echo进程¶
作为一个并发进程的简单示例,我们创建一个echo进程用于原样发回它所接收到的消息。我们假设进程A向echo进程发送消息{A, Msg},则echo进程向A发送一条包含Msg的新消息。如图1.1所示。
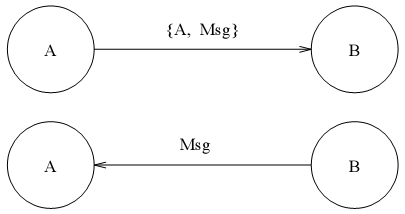
图1.1 一个echo进程
在程序1.5中echo:start()创建一个返回任何发送给它的消息的简单进程。
程序 1.5
-module(echo).
-export([start/0, loop/0]).
start() ->
spawn(echo, loop, []).
loop() ->
receive
{From, Message} ->
From ! Message,
loop()
end.
spawn(echo, loop [])对echo:loop()所表示的函数相对于调用函数并行求值。因此,针对:
...
Id = echo:start(),
Id ! {self(), hello}
...
进行求值将会启动一个并行进程并向该进程发送消息{self(), hello}——self()是用于获取当前进程标识符的BIF。
脚注
| [1] | “实现相关”是指如何完成某个具体操作的细节是系统相关的,也不在本书的讨论范畴之内。 |
| [2] | F/N标记表示具备N个参数的函数F。 |
| [*] | 译者注:在较新版本的Erlang中,该示例的输出为"abc"。当Erlang shell猜测出待打印的列表为字符串时,会尝试以字符串形式输出列表,参见此处。感谢网友孔雀翎指出。 |