第5章 并行编程¶
| 翻译: | 张驰原 |
|---|---|
| 校订: | 连城 |
进程和进程见通信都是Erlang以及所有并行编程中最基本的概念,进程的创建和进程间的通信都是显式进行的。
进程的创建¶
一个进程是一个独立自治的计算单元,它与系统中其他的进程并行地存在。进程之间没有继承的层次关系,不过应用程序的设计者也可以显式地创建这样一个层次关系。
BIF spawn/3创建并开始执行一个新的进程,它的参数和apply/3是一样的:
Pid = spawn(Module, FunctionName, ArgumentList)
和apply不同的是,spawn并不是直接对函数进行求值并返回其结果,而是启动一个新的并行进程用于对函数进行求值,返回值是这个新创建的进程的Pid(进程标识符)。和一个进程的所有形式的交互都是通过Pid来进行的。spawn/3会在启动新进程之后立即返回,而不会等待它对函数完成求值过程。
在图5.1(a)中,我们有一个标识符为Pid1的进程调用了如下函数:
Pid2 = spawn(Mod, Func, Args)
在spawn返回之后,会有两个进程Pid1和Pid2并行地存在,状态如图5.1(b)所示。现在只有进程Pid1知道新进程的标识符,亦即Pid2。由于Pid是一切进程间通讯的必要元素,一个Erlang系统中的安全性也是建立在限制进程Pid分发的基础上的。
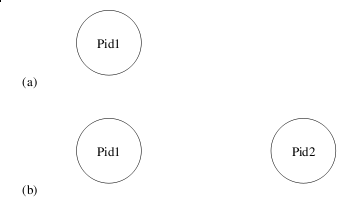
图5.1
当传递给spawn的函数执行完毕之后,进程会自动退出。这个顶层函数的返回值将被丢弃[1]。
进程标识符是一个普通的数据对象,可以像操作其他对象那样对其进行处理。例如,它可以被放到一个列表或元组中,可以与其他标识符进行比较,也可以当做消息发送给其他进程。
进程间通信¶
在Erlang中进行进程间通信的唯一方法就是消息传递。一个消息通过原语!(send)发送给另一个进程:
Pid ! Message
Pid是要向其发送消息的进程的标识符。任何合法的Erlang表达式都可以作为一个消息发送。send是一个会对其参数进行求值的原语。它的返回值是发送的消息。因此:
foo(12) ! bar(baz)
会分别对foo(12)和bar(baz)进行求值得到进程标识符和要发送的消息。如同其他的Erlang函数一样,send对其参数的求值顺序是不确定的。它会将消息参数求值的结果作为返回值返回。发送消息是一个异步操作,因此send既不会等待消息送达目的地也不会等待对方收到消息。就算发送消息的目标进程已经退出了,系统也不会通知发送者。这是为了保持消息传递的异步性──应用程序必须自己来实现各种形式的检查(见下文)。消息一定会被传递到接受者那里,并且保证是按照其发送的顺序进行传递的。
原语receive被用于接收消息。它的语法如下:
receive
Message1 [when Guard1] ->
Actions1 ;
Message2 [when Guard2] ->
Actions2 ;
...
end
每个进程都有一个邮箱,所有发送到该进程的消息都被按照它们到达的顺序依次存储在邮箱里。在上面的例子中,Message1和Message2是用于匹配进程邮箱中的消息的模式。当找到一个匹配的消息并且对应的保护式(Guard)满足的时候,这个消息就被选中,并从邮箱中删除,同时对应的ActionsN会被执行。receive会返回ActionosN中最后一个表达式求值的结果。就如同Erlang里其他形式的模式匹配一样,消息模式中未绑定(unbound)量会被绑定(bound)。未被receive选中的消息会按照原来的顺序继续留在邮箱中,用于下一次recieve的匹配。调用receive的进程会一直阻塞,直到有匹配的消息为止。
Erlang有一种选择性接收消息的机制,因此意外发送到一个进程的消息不会阻塞其它正常的消息。不过,由于所有未匹配的消息会被留在邮箱中,保证系统不要完全被这样的无关消息填满就变成了程序员的责任。
消息接收的顺序¶
当receive尝试寻找一个匹配的消息的时候,它会依次对邮箱中的每一个消息尝试用给定的每个模式去进行匹配。我们用下面的例子来解释其工作原理。
图5.2(a)给出了一个进程的邮箱,邮箱里面有四个消息,依次是msg_1、msg_2、msg_3和msg_4。运行
receive
msg_3 ->
...
end
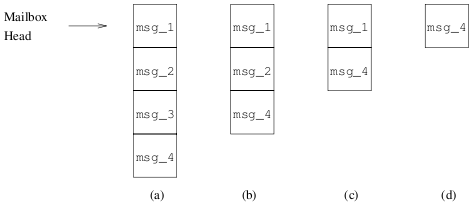
图5.2
会匹配到邮箱中的msg_3并导致它被从邮箱中删除。然后邮箱的状态会变成如图5.2(b)所示。当我们再运行
receive
msg_4 ->
...
msg_2 ->
...
end
的时候,receive会依次对邮箱中的每一个消息,首先尝试与msg_4匹配,然后尝试与msg_2匹配。结果是msg_2匹配成功并被从邮箱中删除,邮箱的状态变成图5.2(c)那样。最后,运行
receive
AnyMessage ->
...
end
其中AnyMessage是一个未绑定(unbound)的变量,receive会匹配到邮箱里的msg_1并将其删除,邮箱中最终只剩下msg_4,如图5.2(d)所示。
这说明receive里的模式的顺序并不能直接用来实现消息的优先级,不过这可以通过超时的机制来实现,详见第??小节。
只接收来自某个特定进程的消息¶
有时候我们会只希望接收来自某一个特定进程的消息。要实现这个机制,消息发送者必须显式地在消息中包含自己的进程标识符:
Pid | {self(),abc}
BIF self()返回当前进程的标识符。这样的消息可以通过如下方式来接收:
receive
{Pid,Msg} ->
...
end
如果Pid已经预先绑定(bound)到发送者的进程标识符上了,那么如上所示的receive就能实现只接收来自该进程[2]的消息了。
一些例子¶
程序5.1中的模块实现了一个简单的计数器,可以用来创建一个包含计数器的进程并对计数器进行递增操作。
程序 5.1
-module(counter).
-export([start/0,loop/1]).
start() ->
spawn(counter, loop, [0]).
loop(Val) ->
receive
increment ->
loop(Val + 1)
end.
这个例子展示了一些基本概念:
- 每个新的计数器进程都通过调用counter:start/0来创建。每个进程都会以调用counter:loop(0)启动。
- 用于实现一个永久的进程的递归函数调用在等待输入的时候会被挂起。loop是一个尾递归函数,这让计数器进程所占用的空间保持为一个常数。
- 选择性的消息接收,在这个例子中,仅接收increment消息。
不过,在这过例子中也有不少缺陷,比如:
- 由于计数器的值是一个进程的局部变量,只能被自己访问到,却其他进程没法获取这个值。
- 消息协议是显式的,其他进程需要显式地发送increment消息给计数器进程。
程序5.2
-module(counter).
-export([start/0,loop/1,increment/1,value/1,stop/1]).
%% First the interface functions.
start() ->
spawn(counter, loop, [0]).
increment(Counter) ->
Counter ! increment.
value(Counter) ->
Counter ! {self(),value}
receive
{Counter,Value} ->
Value
end.
stop(Counter) ->
Counter ! stop.
%% The counter loop.
loop(Val) ->
receive
increment ->
loop(Val + 1);
{From,value} ->
From ! {self(),Val},
loop(Val);
stop -> % No recursive call here
true;
Other -> % All other messages
loop(Val)
end.
下一个例子展示了如何修正这些缺陷。程序5.2是counter模块的改进版,允许对计数器进行递增、访问计数器的值以及停止计数器。
同前一个例子中一样,在这里一个新的计数器进程通过调用counter::start()启动起来,返回值是这个计数器的进程标识符。为了隐藏消息传递的协议,我们提供了接口函数increment、value和stop来操纵计数器。
计数器进程使用选择性接收的机制来处理发送过来的请求。它同时展示了一种处理未知消息的方法。通过在receive的最后一个子句中使用未绑定(unbound)的变量Other作为模式,任何未被之前的模式匹配到的消息都会被匹配到,此时我们直接忽略这样的未知消息并继续等待下一条消息。这是处理未知消息的标准方法:通过receive把它们从邮箱中删除掉。
为了访问计数器的值,我们必须将自己的Pid作为消息的一部分发送给计数器进程,这样它才能将回复发送回来。回复的消息中也包含了发送方的进程标识符(在这里也就是计数器进程的Pid),这使得接收进程可以只接收包含回复的这个消息。简单地等待一个包含未知值(在这个例子中是一个数字)的消息是不安全的做法,任何不相关的碰巧发送到该进程的消息都会被匹配到。因此,在进程之间发送的消息通常都会包含某种标识自己的机制,一种方法是通过内容进行标识,就像发送给计数器进程的请求消息一样,另一种方法是通过在消息中包含某种“唯一”并且可以很容易识别的标识符,就如同计数器进程发回的包含计数器值的回复消息一样。
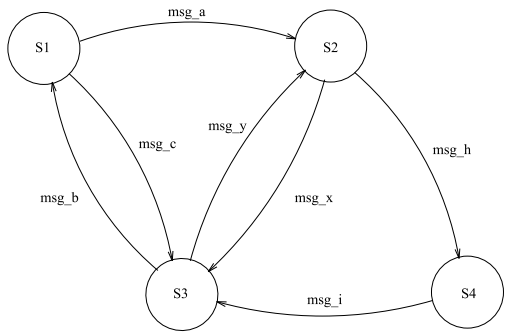
图5.3
现在我们再来考虑对一个有穷自动机(FSM)进行建模。图5.3展示了一个4状态的简单FSM以及可能的状态转移和相应的触发事件。一种编写这样的“状态-事件”机器的方法如程序5.3所示。在这段代码中,我们只专注于如何表示状态以及管理状态之间的转移。每个状态由一个单独的函数表示,而事件则表示为消息。
程序 5.2
s1() ->
receive
msg_a ->
s2();
msg_c ->
s3()
end.
s2() ->
receive
msg_x ->
s3();
msg_h ->
s4()
end.
s3() ->
receive
msg_b ->
s1();
msg_y ->
s2()
end.
s4() ->
receive
msg_i ->
s3()
end.
转台函数通过receive来等待事件所对应的消息。当收到消息时,FSM通过调用相应的状态函数转移到指定的状态。通过保证每次对于新状态的函数的调用都是最后一个语句(参见第??小节),FSM进程可以在一个常数大小的空间中进行求值。
状态数据可以通过为状态函数添加参数的方式来处理。需要在进入状态的时候执行的动作在调用receive之前完成,而需要在离开状态时执行的动作可以放在对应的receive子句中调用新的状态函数之前。
超时¶
Erlang中用于接收消息的基本原语receive可以通过添加一个可选的超时子句来进行增强,完整的语法变成这样:
receive
Message1 [when Guard1] ->
Actions1 ;
Message2 [when Guard2] ->
Actions2 ;
...
after
TimeOutExpr ->
ActionsT
end
TimeOutExpr是一个整数值表达式,表示毫秒数。时间的精确程度受到具体Erlang实现的底层操作系统以及硬件的限制——这是一个局部性问题(local issue)。如果在指定的时间内没有任何消息被匹配到,超时将会发生,ActionsT会被执行,而具体什么时候执行则是依赖与很多因素的,比如,和系统当前的负载有关系。
例如,对于一个窗口系统,类似于下面的代码可能会出现在处理事件的进程中:
get_event() ->
receive
{mouse, click} ->
receive
{mouse, click} ->
double_click
after double_click_interval() ->
single_click
end
...
end.
在这个模型中,事件由消息来表示。get_event函数会等待一个消息,然后返回一个表示对应事件的原子式。我们希望能检测鼠标双击,亦即在某一个较短时间段内的连续两次鼠标点击。当接收到一个鼠标点击事件时我们再通过receive试图接收下一个鼠标点击事件。不过,我们为这个receive添加了一个超时,如果在指定的时间内(由double_click_interval指定)没有发生下一次鼠标点击事件,receive就会超时,此时get_event会返回single_click。如果第二个鼠标点击事件在给定的超时时限之内被接收到了,那么get_event将会返回double_click。
在超时表达式的参数中有两个值有特殊意义:
infinity
原子式infinity表示超时永远也不会发生。如果超时时间需要在运行时计算的话,这个功能就很有用。我们可能会希望通过对一个表达式进行求值来得到超时长度:如果返回值是infinity的话,则永久等待。
0
数值0表示超时会立即发生,不过在那之前系统仍然会首先尝试对邮箱中已有的消息进行匹配。
在receive中使用超时比一下子想象到的要有用得多。函数sleep(Time)将当前进程挂起Time毫秒:
sleep(Time) ->
receive
after Time ->
true
end.
flush_buffer()清空当前进程的邮箱:
flush_buffer() ->
receive
AnyMessage ->
flush_buffer()
after 0 ->
true
end.
只要邮箱中还有消息,第一个消息会被匹配到(未绑定变量AnyMessage会匹配到任何消息,在这里就是第一个消息),然后flush_buffer会再次被调用,但是如果邮箱已经为空了,那么函数会从超时子句中返回。
消息的优先级也可以通过使用0作为超时长度来实现:
priority_receive() ->
receive
interrupt ->
interrupt
after 0 ->
receive
AnyMessage ->
AnyMessage
end
end
函数priority_receive会返回邮箱中第一个消息,除非有消息interrupt发送到了邮箱中,此时将返回interrupt。通过首先使用超时时长0来调用receive去匹配interrupt,我们可以检查邮箱中是否已经有了这个消息。如果是,我们就返回它,否则,我们再通过模式AnyMessage去调用receive,这将选中邮箱中的第一条消息。
程序 5.4
-module(timer).
-export([timeout/2,cancel/1,timer/3]).
timeout(Time, Alarm) ->
spawn(timer, timer, [self(),Time,Alarm]).
cancel(Timer) ->
Timer ! {self(),cancel}.
timer(Pid, Time, Alarm) ->
receive
{Pid,cancel} ->
true
after Time ->
Pid ! Alarm
end.
在receive中的超时纯粹是在receive语句内部的,不过,要创建一个全局的超时机制也很容易。在程序5.4中的timer模块中的timer::timeout(Time,Alarm)函数就实现了这个功能。
调用timer:timeout(Time, Alarm)会导致消息Alarm在时间Time之后被发送到调用进程。该函数返回计时器进程的标识符。当进程完成自己的任务之后,可以使用该计时器进程标识符来等待这个消息。通过调用timer::cancel(Timer),进程也可以使用这个标识符来撤销计时器。需要注意的是,调用timer:cancel并不能保证调用进程不会收到Alarm消息,这是由于cancel消息有可能在Alarm消息被发送出去之后才被收到的。
注册进程¶
为了向一个进程发送消息,我们需要事先知道它的进程标识符(Pid)。在某些情况下,这有些不切实际甚至不太合理。比如,在一个大型系统中通常存在许多全局服务器,或者某个进程由于安全方面的考虑希望隐藏它自己的标识符。为了让一个进程在并不事先知道对方的进程标识符的情况下向其发送消息,我们提供了注册进程的机制,换句话说,给进程一个名字。注册进程的名字必须是一个原子式。
基本原语¶
Erlang提供了四个BIF来操纵注册进程的名字:
register(Name, Pid)
将原子式Name关联到进程Pid。
unregister(Name)
删除原子式Name与对应进程的关联。
whereis(Name)
返回关联到注册名Name的进程标识符,如果没有任何进程关联到这个名字,则返回原子式undefined。
registered()
返回一个包含所有当前已注册过的名字。
消息发送的原语“!” 允许直接使用一个注册进程的名字作为目标,例如:
number_analyzer ! {self(), {analyse,[1,2,3,4]}}
表示将消息{Pid,{analyse,[1,2,3,4]}}发送到注册为numeber_analyser的进程那里。Pid是调用send的进程的标识符。
“客户端-服务端”模型¶
注册进程的一个主要用途就是用于支持“客户端-服务端”模型编程。在这个模型中有一个服务端管理着一些资源,一些客户端通过向服务端发送请求来访问这些资源,如图5.4所示。要实现这个模型,我们需要三个基本组件——一个服务端,一个协议和一个访问库。我们将通过几个例子来阐明基本原则。
在先前的程序5.2中展示的counter模块里,每一根计数器都是一个服务端。客户端通过调用模块所定义的函数来访问服务端。
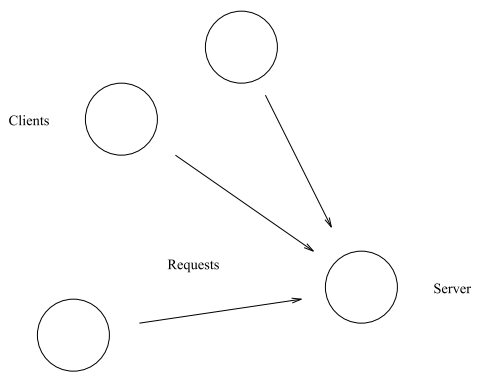
图5.4
程序5.5中展示的例子是一个可以用于电话交换机系统里分析用户所拨打的号码的服务端。start()会调用spawn并将新建的进程注册为number_analyser,这就完成了号码分析服务端的创建。之后服务端进程会在server函数中不断循环并等待服务请求。如果收到了一个形如{add_number,Seq,Dest}的请求,该号码序列(Seq)以及对应的目标进程(Dest),以及分析出结果之后将会发送的目的地,会被添加到查找表中。这是由函数insert完成的。之后消息ack将会被发送到请求的进程。如果服务端收到了形如{analyse,Seq}的消息,那么它将通过调用lookup完成号码序列Seq的分析,并将包含分析结果的消息发回发送请求的进程。我们在这里没有给出函数insert和lookup的具体定义,因为那对于我们目前讨论的问题而言并不重要。
客户端发送到服务端的请求消息包含了自己的进程标识符。这让服务端可以向客户端发送回复。发回的回复消息中也包含了一个“发送者”的标识,在这里就是服务端的注册名字,这使得客户端可以选择性地接收回复消息。这比简单地等待第一个消息到达要更加安全一些——因为客户端的邮箱中也许已经有了一些消息,或者其他进程也许会在服务端回复之前给客户端发送一些消息。
程序 5.5
-module(number_analyser).
-export([start/0,server/1]).
-export([add_number/2,analyse/1]).
start() ->
register(number_analyser,
spawn(number_analyser, server, [nil])).
%% The interface functions.
add_number(Seq, Dest) ->
request({add_number,Seq,Dest}).
analyse(Seq) ->
request({analyse,Seq}).
request(Req) ->
number_analyser ! {self(), Req},
receive
{number_analyser, Reply} ->
Reply
end.
%% The server.
server(AnalTable) ->
receive
{From, {analyse,Seq}} ->
Result = lookup(Seq, AnalTable),
From ! {number_analyser, Result},
server(AnalTable);
{From, {add_number, Seq, Dest}} ->
From ! {number_analyser, ack},
server(insert(Seq, Dest, AnalTable))
end.
现在我们已经实现了服务端并定义了协议。我们在这里使用了一个异步协议,每个发送到服务端的请求都会有一个回复。在服务端的回复中我们使用number_analyser(亦即服务端的注册名字)作为发送者标识,这样做是因为我们不希望暴露服务端的Pid。
接下来我们定义一些接口函数用于以一种标准的方式访问服务端。函数add_number和analyse按照上面描述的方式实现了客户端的协议。它们都使用了局部函数request来发送请求并接收回复。
程序5.6
-module(allocator).
-export([start/1,server/2,allocate/0,free/1]).
start(Resources) ->
Pid = spawn(allocator, server, [Resources,[]]),
register(resource_alloc, Pid).
% The interface functions.
allocate() ->
request(alloc).
free(Resource) ->
request({free,Resource}).
request(Request) ->
resource_alloc ! {self(),Request},
receive
{resource_alloc,Reply} ->
Reply
end.
% The server.
server(Free, Allocated) ->
receive
{From,alloc} ->
allocate(Free, Allocated, From);
{From,{Free,R}} ->
free(Free, Allocated, From, R)
end.
allocate([R|Free], Allocated, From) ->
From ! {resource_alloc,{yes,R}},
server(Free, [{R,From}|Allocated]);
allocate([], Allocated, From) ->
From ! {resource_alloc,no},
server([], Allocated).
free(Free, Allocated, From, R) ->
case lists:member({R,From}, Allocated) of
true ->
From ! {resource_alloc,ok},
server([R|Free], lists:delete({R,From}, Allocated));
false ->
From ! {resource_alloc,error},
server(Free, Allocated)
end.
下一个例子是如程序5.6中所示的一个简单的资源分配器。服务端通过一个需要管理的初始的资源列表来启动。其他进程可以向服务端请求分配一个资源或者将不再使用的资源释放掉。
服务端进程维护两个列表,一个是未分配的资源列表,另一个是已分配的资源列表。通过将资源在两个列表之间移动,服务端可以追踪每个资源的分配情况。
当服务端收到一个请求分配资源的消息时,函数allocate/3会被调用,它会检查是否有未分配的资源存在,如果是则将资源放在回复给客户端的yes消息中发送回去,否则直接发回no消息。未分配资源列表是一个包含所有未分配资源的列表,而已分配资源列表是一个二元组{Resource,AllocPid}的列表。在一个资源被释放之前,亦即从已分配列表中删除并添加到未分配列表中去之前,我们首先会检查它是不是一个已知的资源,如果不是的话,就返回error。
讨论¶
接口函数的目的是创建一个抽象层并隐藏客户端和服务端之间使用的协议的细节。一个服务的用户在使用服务的时候并不需要知道协议的细节或者服务端所使用的内部数据结构以及算法。一个服务的具体实现可以在保证外部用户接口一致性的情况下自由地更改这些内部细节。
此外,回复服务请求的进程还有可能并不是实际的服务器进程,而是一个不同的进程——所有的请求都被委转发到它那里。实际上,“一个”服务器可能会是一个巨大的进程网络,这些互通的进程一起实现了给定的服务,但是却被接口函数隐藏起来。应当发布的是接口函数的集合,它们应当被暴露给用户,因为这些函数提供了唯一合法的访问服务端提供的服务的方式。
在Erlang中实现的“客户端-服务端”模型是非常灵活的。monitor或remote procedure call之类的机制可以很容易地实现出来。在某些特殊的情况下,具体实现也可以绕过接口函数直接与服务端进行交互。由于Erlang并没有强制创建或使用这样的接口函数,因此需要由系统设计师来保证在需要的时候创建它们。Erlang并没有提供用于远程过程调用之类的现成解决方案,而是提供了一些基本原语用于构造这样的解决方案。
进程调度,实时性以及优先级¶
到目前为止我们还没有提到过一个Erlang系统中的进程是如何调度的。虽然这是一个实现相关的问题,但是也有一些所有实现都需要满足的准则:
- 调度算法必须是公平的,换句话说,任何可以运行的进程都会被执行,并且(如果可能的话)按照它们变得可以运行的顺序来执行。
- 不允许任意一个进程长期阻塞整个系统。一个进程被分配一小段运行时间(称为时间片),再那之后它将被挂起并等待下一次运行调度,以使得其他可运行的进程也有机会运行。
典型情况下,时间片被设为可以让当前进程完成500次规约(reduction)[3]的时间。
Erlang语言实现的一个要求是要保证让它能够适用于编写软实时的应用程序,也就是说,系统的反应时间必须至少是毫秒级别的。一个满足以上准则的调度算法通常对于一个这样的Erlang实现来说已经足够了。
要让Erlang系统能应用于实时应用程序的另一个重要的特性是内存管理。Erlang对用户隐藏了所有的内存管理工作。内存在需要的时候被自动分配并在不需要之后一段时间内会被自动回收。内存的分配和回收的实现必须要保证不会长时间地阻塞系统的运行,最好是比一个时间片更短,以保证不会影响其实时性。
进程优先级¶
所有新创建的进程都在运行在同一个优先级上。不过有时候也许会希望一些进程以一个比其他进程更高或更低的优先级运行:例如,一个用于跟踪系统状态的进程也许只需要偶尔运行一下。BIF process_flag可以用来改变进程的优先级:
process_flag(priority, Pri)
Pri是进程的新的优先级,可以是normal或者low,这将改变调用该BIF的进程的运行优先级。优先级为normal的进程会比优先级为low的进程运行得更加频繁一些。所有进程默认的优先级都是normal。
进程组¶
所有Erlang进程都有一个与其相关联的Pid,称作进程的组长。当一个新进程被创建时,它会被自动归属到调用spawn语句的那个进程所属的进程组中。一开始,系统中的第一关进程是它自身的组长,因此也是所有后来创建的进程的组长。这表示所有的Erlang进程被组织为一个树形结构,第一个进程是树根。
以下的BIF可以被用于操控进程组:
group_leader()
返回调用该BIF的进程的组长Pid。
group_leader(Leader, Pid)
将进程Pid的组长设置为Leader。
Erlang的输入输出系统中用到了进程组的概念,详见第??章的描述。
脚注
| [1] | 因为并没有专门用于存放这些计算结果的地方。 |
| [2] | 或者其他知道该进程标识符的进程。 |
| [3] | 一次规约(reduction)等价于一次函数调用。 |